本文翻译自 MuZero Intuition ,加入了一点自己的理解。原博客下面还有许多讨论,可以看看。
为了庆祝我们的MuZero论文在Nature (full-text)上发表,我写了一篇关于MuZero算法的简单描述。本文是给你一个直观的理解和算法的总体概述:要了解全部细节,请阅读paper。也请参阅我们的 official DeepMind blog post。
MuZero是一个非常令人兴奋的进步,它不需要游戏规则或环境变化的特殊知识,而是自己学习环境模型并使用该模型进行规划。尽管MuZero使用学习出来的环境模型进行规划,但它的规划效果和AlphaZero一样好——为将其应用于许多现实世界的问题打开了大门!
都是统计
Muzero是一种机器学习算法,所以第一个需要理解的就是它是如何使用神经网络的。从AlphaGo到AlphaZero,它对策略网络和价值网络的使用是一样的。1
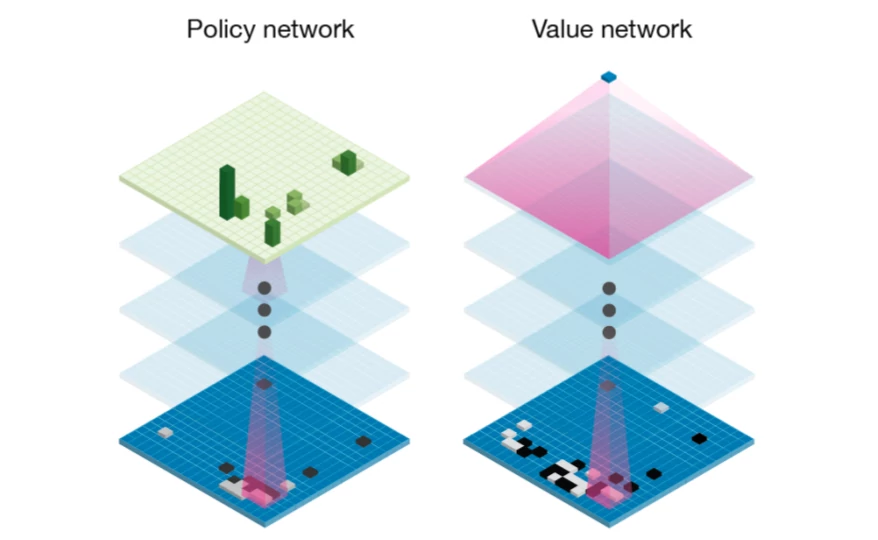
策略网络和价值网络都有非常直观的含义:
- 策略网络
是状态s下,做出动作a的概率。它估计了哪个动作可能是最优动作。它类似于人类棋手快速看了一眼棋盘后,对下一步棋的初步猜测。 - 价值网络
估计当前状态s往后赢的概率。考虑所有可能的未来状态,它们出现的概率有多大?其中有多少状态当前玩家能赢?
这些网络本身就已经非常强大了:如果你只有一个策略网络,你就可以简单地按照它预测的最可能的移动方式行事,最终得到一个非常不错的玩家。同样地,只给你一个价值网络,你总是可以选择价值最高的行动。然而,将两种估计结合起来会得到更好的结果。
计划取胜
类似于之前的AlphaGo和AlphaZero,Muzero使用Monte Carlo Tree Search(MTCS)2来结合神经网络的预测选择用于环境的动作。
MTCS是迭代式的,best-first的树搜索。Best-first是说用节点的价值估计来指导搜索树的扩展。相较于经典的广度优先和深度优先,最佳优先搜索可以利用启发式估计(如神经网络),即在非常大的搜索空间中找到不错的解决方案。
MCTS主要有三个阶段:模拟、扩展和反向传播。通过重复执行这些阶段,MCTS逐步的构建一个搜索树,每次扩展一个节点。在此树中,每个节点都是一个未来状态,而节点之间的边表示从一个状态到下一个状态的动作。
在我们深入讨论细节之前,让我先介绍一下这种搜索树的示意图,包括MuZero所做的神经网络预测:
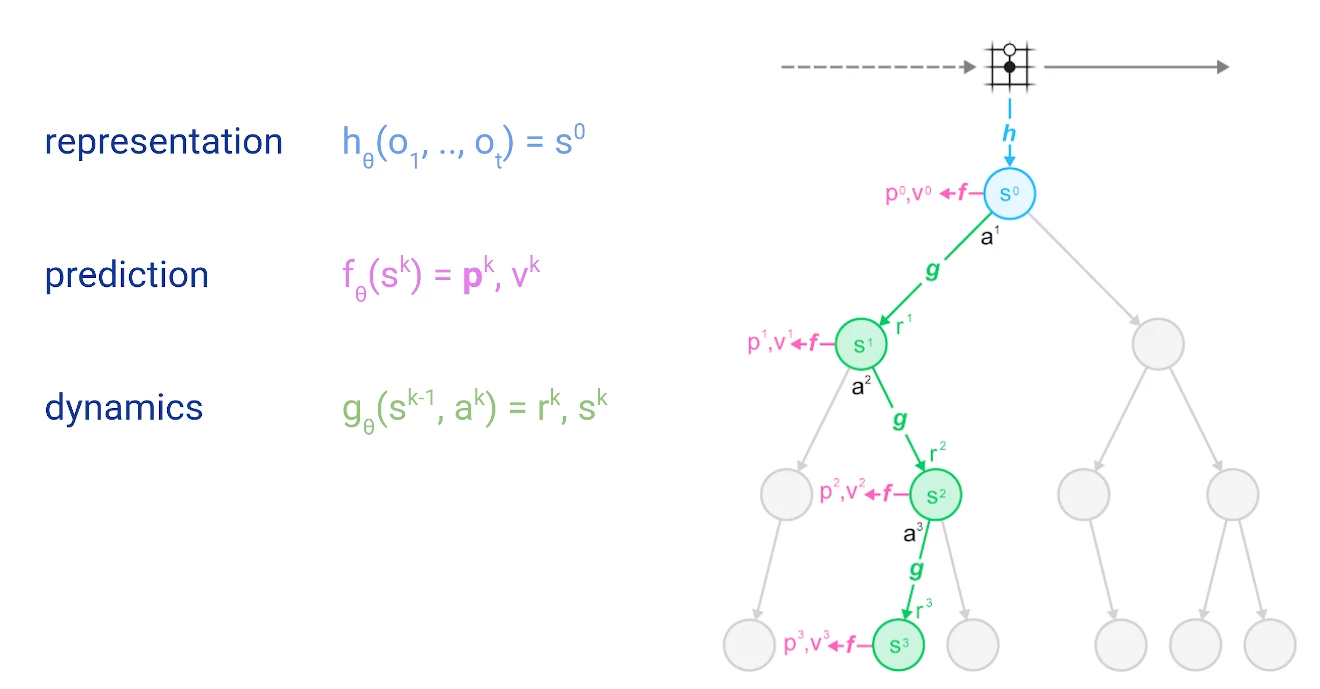
圆圈表示树的节点,对应于环境中的状态。线条代表动作,从一个状态引导到下一个状态。树的根在顶部,表示当前的环境状态。我们将在后面的章节中详细介绍表示、预测和动态函数。
模拟总是从树的根节点开始(图中蓝色节点),表示当前环境状态。对每个节点(状态s),它使用评分函数来
其中缩放系数c3是为了确保随着我们的价值估计v(s,a)变得更准确,先验估计p(s,a)的影响会减少。
每次选择一个动作时,我们增加相关边的访问计数
模拟沿着树进行,直到到达尚未展开的叶子;在这一点上,神经网络被用来评估节点。评估结果(先验估计
扩展:一旦一个未被扩展的节点达到一定的评估次数,它就被标记为“已扩展”。被扩展意味着子节点可以被添加到节点;这使得可以增加搜索的深度。在MuZero中,扩展阈值为1,即每个节点在第一次被评估后立即被标记为已扩展。更高的扩展阈值有助于在深入搜索之前收集更可靠的统计数据4。
反向传播:最后,从神经网络评估中得到的价值估计沿搜索树反向传播。每个节点保持其下方所有价值估计的平均值。随着时间的推移,这种平均过程使UCB公式能够做出越来越准确的决策,从而确保MCTS最终收敛到最佳策略。
中间奖励
一些聪明的读者可能注意到上面的图还包括对r的预测。一些场景,比如棋盘游戏,只在一局游戏结束后提供反馈(e.g. 输/赢)。它们仅仅通过价值估计就可以建模。然而其它场景可能提供更频繁的反馈,比如当从一个状态做了动作转移到另一个状态后会有奖励r(s,a)。
通过神经网络预测直接建模这种奖励,并将其用于搜索是有利的。只需要稍微修改一下UCB公式:
其中
由于一般情况下奖励可以是任意尺度的,我们进一步将奖励/价值估计归一化,使其位于区间[0,1],然后再与先验估计相加:
其中
每局生成
上面描述的MTCS过程,可以不断的应用于每个新的状态,最终完成一局游戏:
- 基于当前环境状态
进行MTCS搜索 - 基于搜索统计出的策略
选择动作 - 对环境
应用动作 ,进入下一个状态 ,并观察到奖励 - 重复上述过程直到环境结束
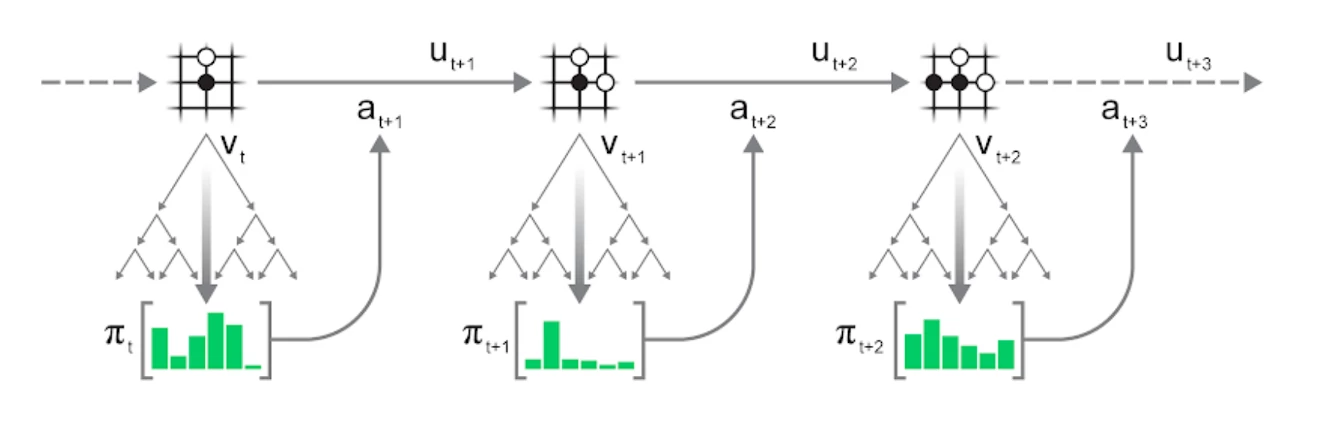
可以贪婪的选择动作,即选择访问次数n最多的动作。也可以探索性的选择动作,即以正比于访问次数的概率来选择动作。下面的式子使用温度参数t来控制探索的程度。
t=0时,就是贪婪的选择动作,t=inf时,就是均匀选择动作。t=1时就是正比于访问次数来选择动作。上式的
训练
现在我们知道如何通过运行MTCS来选择更好的动作,与环境交互并生成对局,接下来我们要看如何训练模型了。
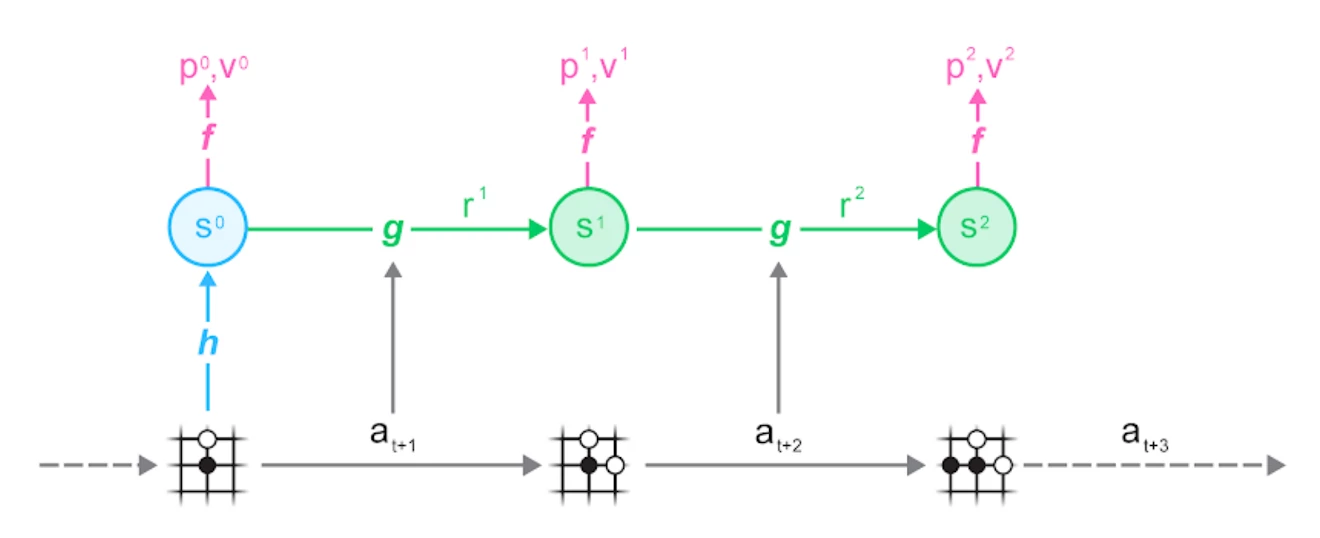
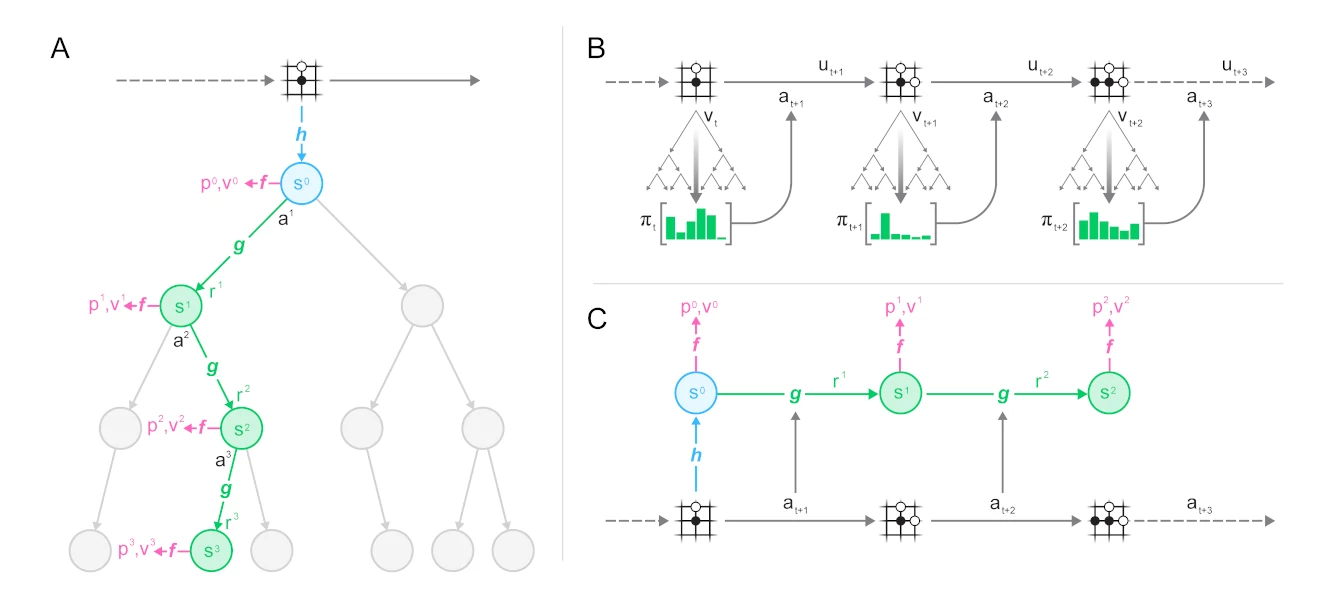
可以看到Muzero的模型分为三个部分:
- 表示函数
将一系列观察映射到隐藏状态 - 动态函数
输入隐藏状态和动作,预测下一个隐藏状态和当前动作的奖励。这个模型让Muzero可以在隐藏状态空间通过MTCS进行规划,而不需要和环境交互。 - 预测函数
根据当前状态 估计下一时刻的动作 和当前状态的价值 . 这些估计被用于在MTCS的过程中更新UCB公式,对哪个动作价值更高做出更好的估计。
在训练时,实际的观测和动作作为输入,各个状态预测出来的的策略p、价值v还有中间的奖励r,作为标签计算损失。
你可以更清楚的在下图B和图C中看到对局生成和训练阶段的对应关系。
具体而言,Muzero对这三个输出的训练损失如下:
- 策略:输出策略的logits与MTCS的动作访问计数的交叉熵
- 价值:往后N步奖励的折扣和+MTCS搜索出来的价值/目标网络的价值估计 与 预测出来的价值做交叉熵/mean squared error 5
- 奖励:动态函数估计的奖励和实际奖励的交叉熵
(小疑惑:在下棋里是自己和对手交替落子,这里MCTS的价值是怎么算的?在不是下棋的场景里又有什么不同?应该看看作者的伪代码比较好todo )
重分析
reanalyse
明白了MuZero核心训练过程后,我们可以看一看利用搜索来大幅提升数据高效性的方法:重分析。
在一般的训练过程中,我们生成了很多对局轨迹(和环境的交互记录)并且将他们存储在replay buffer中用于后续训练。我们能更多的利用这种数据吗?

因为之前经历过的轨迹已经确定了,我们不能修改状态,动作,或者得到的奖励。但我们也不需要修改作为模型输入的轨迹,我们可以通过修改作为标签的参考策略p和价值v来继续训练。而因为Muzero有动态函数g,我们可以从任意一个状态开始进行MCTS,搜索到一个更好的策略标签p和价值估计v作为新的训练目标。这也相当合理,不同阶段的人对过去的事情也会有不同看法,温故而知新嘛。(对ppo来说应该也重复使用轨迹,但是需要用最新的价值函数来估计优势函数。而训练新的价值函数需要用新策略在环境中采样)
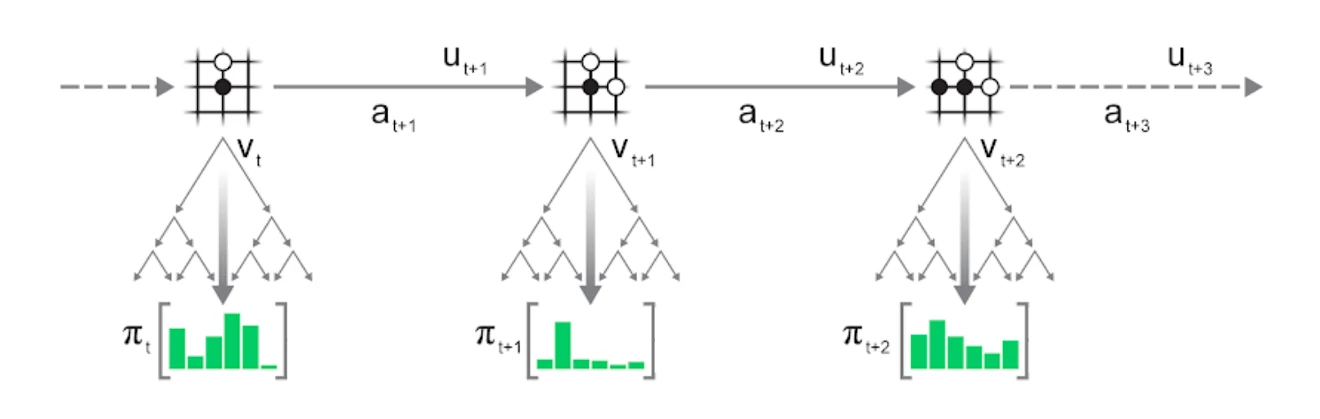
当直接与环境交互时,使用改进的网络进行搜索可以获得更好的搜索统计数据,同样,在保存的轨迹上使用改进的网络重新运行搜索也可以获得更好的搜索统计数据,从而允许使用相同的轨迹数据进行进一步改进。
重分析可以很好的放到MuZero训练循环中。正常的训练循环如下:
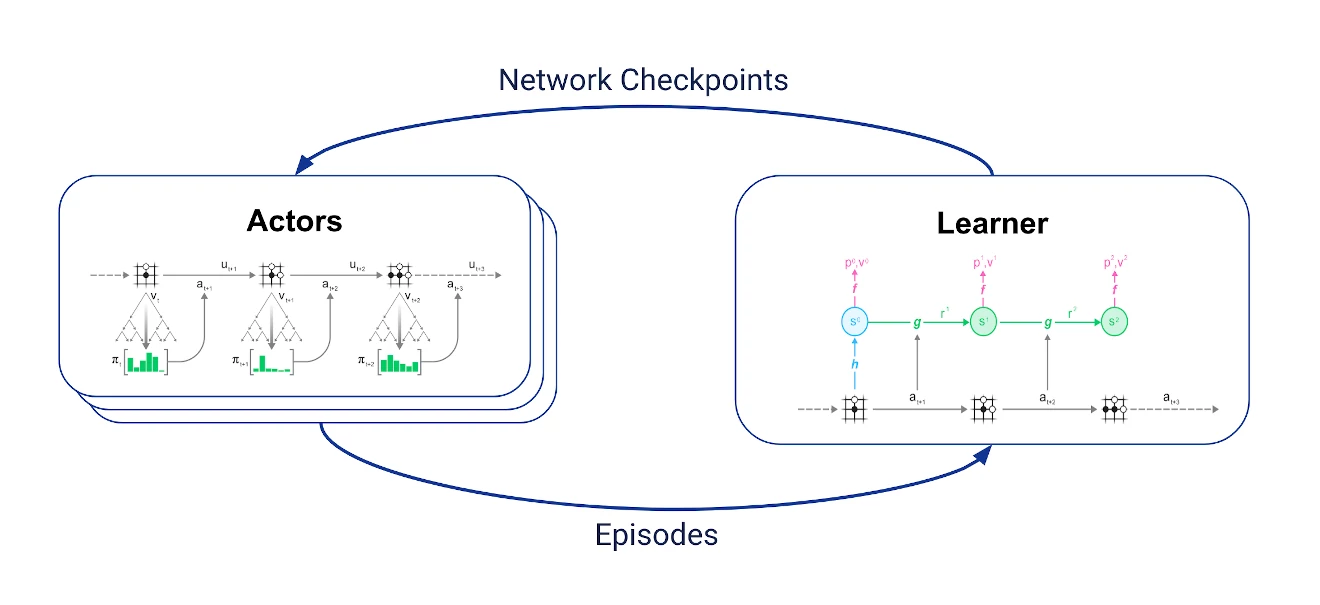
我们有两组彼此异步通信的jobs:
- Learner接收最新的轨迹,将最新的轨迹保存在replay buffer中,并使用它们来执行上述训练算法。
- 多个actor定期从学习者那里获取最新的网络检查点,使用MCTS中的网络来选择动作并与环境交互以生成轨迹。
加入重分析的结果如下,引入了两种jobs:
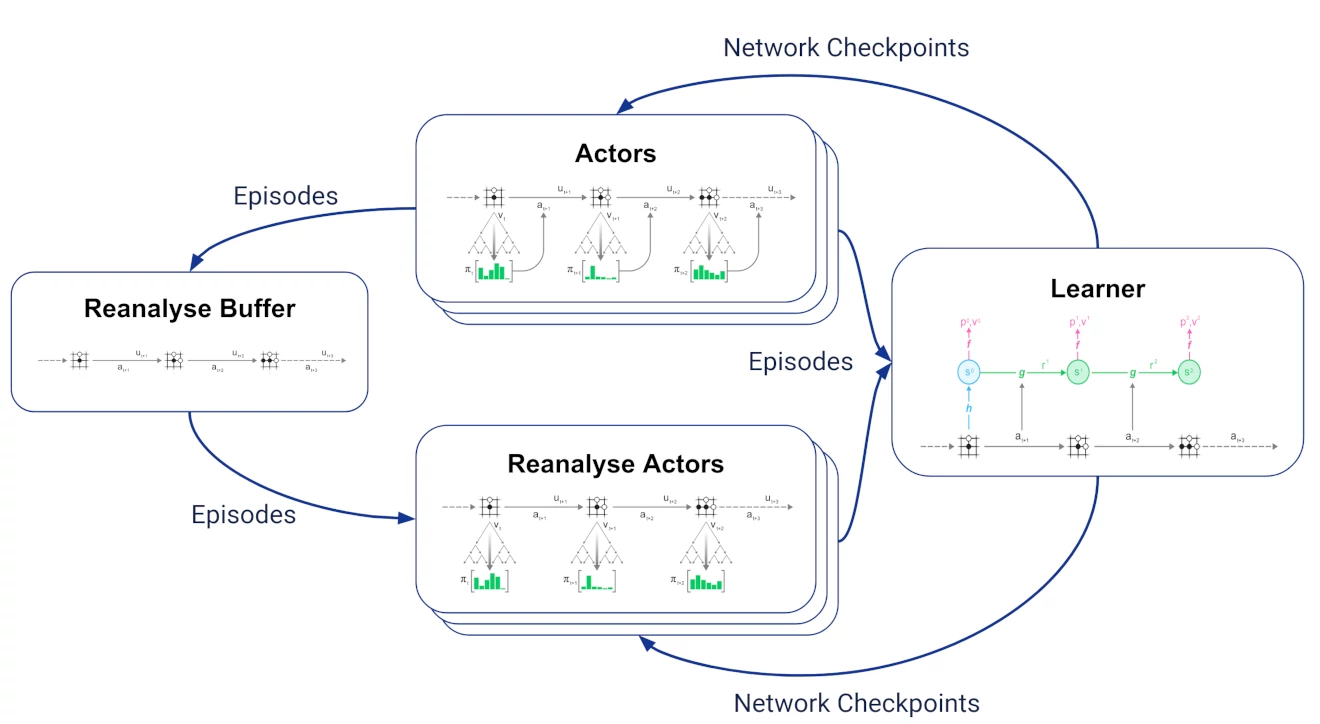
- reanalyse buffer接收actor生成的所有对局数据,并保留最近的数据。
- 多个reanalyse actor6从reanalyse buffer里采样对局轨迹,用learner提供的最新网络checkpoints对旧数据进行重分析。并把结果轨迹发送回learner用于训练。
对learner来说,新策略的轨迹数据和旧策略生成的轨迹数据是一样的,因此很调整新数据和旧数据的比例。
名字的含义
MuZero的名字当然是基于AlphaZero——保留Zero表示它没有模仿人类数据进行训练,用Mu代替Alpha表示它现在使用学习出来的模型进行计划。
再深入挖掘一下,我们就会发现Mu蕴含着丰富的含义:
- 夢在日语中可以读作mu,意思是“梦”——就像MuZero使用学习模型来想象未来的场景一样。
- 希腊字母μ,发音为mu,也可以代表学习模型。
- 無,在日语中发音为mu,意思是“没有”——将从头开始学习的概念加倍:不仅没有可以模仿的人类数据,甚至没有提供规则。(即没有像AlphaZero用环境模拟器做规划)
Final Words
I hope this summary of MuZero was useful!
If you are interested in more details, start with the full paper (pdf). I also gave talks about MuZero at NeurIPS (poster) and most recently at ICAPS. Also see the up-to-date pseudocode.
Let me finish by linking some articles, blog posts and GitHub projects from other researchers that I found interesting:
- A Simple Alpha(Go) Zero Tutorial
- MuZero General implementation
- How To Build Your Own MuZero AI Using Python
Footnotes
-
为简单起见,在MuZero中,这两种预测都是由一个网络,即预测函数做出的。 ↩
-
Introduced by Rémi Coulom in Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search, 2006, MCTS lead to a major improvement in the playing strength of all Go playing programs. “Monte Carlo” in MCTS refers to random playouts used in Go playing programs at the time, estimating the chance of winning in a particular position by playing random moves until the end of the game. ↩
-
MuZero中使用的确切的缩放系数是
,其中 是在状态s下选择动作a的次数, ,它们反应了先验估计相对于价值估计的重要程度。当 时,log项趋近于0,此时公式简化为 ↩ -
这在使用随机评估函数(如AlphaGo之前的许多围棋程序使用的随机策略展开)时非常有用。如果评估函数是确定性的(比如标准的神经网络),多次评估相同的节点就不太有用了。 ↩
-
For board games, the discount γ is 1 and the number of TD steps infinite, so this is just prediction of the Monte Carlo return (winner of the game). (TD steps是说采用几步之后的v作为目标,棋盘游戏就是指轨迹最终的输赢) ↩
-
在我们的MuZero实现中,没有单独的actor集用于重新分析:我们有一组单独的actor集,它们在每个对局开始时决定是启动与环境交互的新轨迹,还是重分析旧的轨迹。 ↩