1412.6980v8.pdf
伪代码如下:
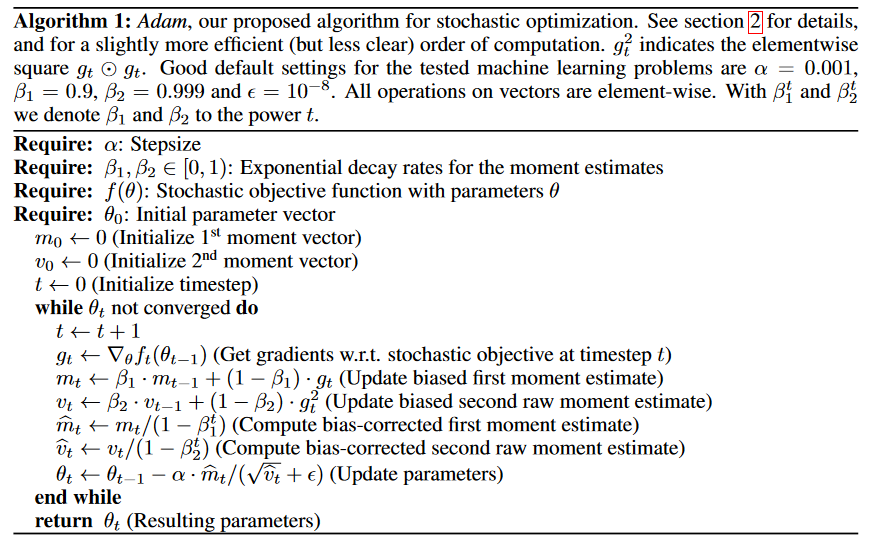
反向传播后,每个可训练参数都有对应的梯度。我们需要对梯度
估计出来当前时刻的梯度下降平均方向和平均步长后,我们就用
我自己一开始看的时候,比较迷惑的是这里的bias correction到底是怎么算的。下面给一个解释
下面是通过迭代的方式计算
展开得到
我们是希望它在对过去各个时候的梯度做加权和,希望权重之和为1。但是上面这个式子的权重和不等于1
所以只要对
权重和等于
所以
为一阶动量,代表惯性,当前梯度的更新方向不仅要考虑当前梯度,还要考虑历史梯度。不希望被当前单个更新方向影响太大。 为二阶动量,用于控制自适应学习率,在分母位置,其物理意义在于: - 对于经常更新的参数,不希望被单个样本影响太大,希望学习率慢一点
- 对于偶尔更新的参数,希望能从少量的样本中多学一些,即学习率大一些
[PDF] Fixing Weight Decay Regularization in Adam | Semantic Scholar
在sgd中,对权重的L2正则化和weight decay是一样的,因此可以通过在损失里加一个权重L2正则项来限制权重,防止过拟合。在loss里对权重
但是在adam等自适应梯度下降算法里,在loss里加L2正则化和weight decay是不同的。当把L2范数直接作用在损失函数上时,L2范数会参与动量和方差的估计(下图中粉色部分,图中的
实验证明AdamW的做法效果更好,想约束权重就直接约束,不要在loss里间接约束。
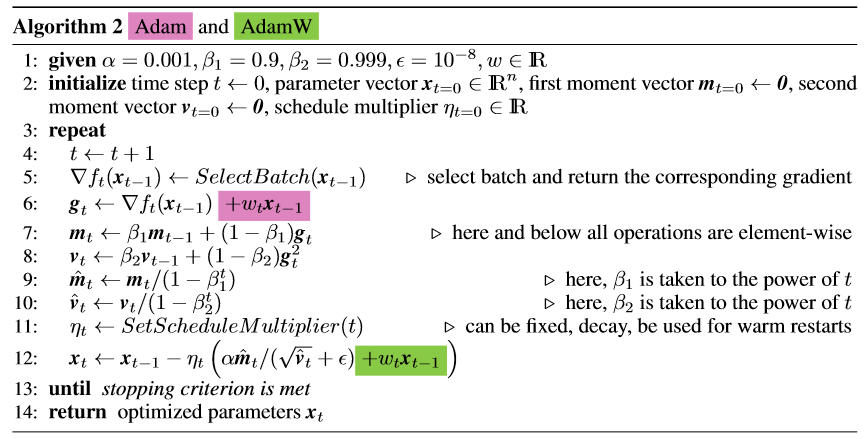
图中”学习率“有
(在llm.c的实现里没有
(其实也可以把weight decay系数