并行方式原理介绍
单卡内:混合精度训练 ,Gradient Checkpointing
为了适应大型分布式训练的模型结构:MoE
各种并行策略如何结合
大模型PTD并行后如何配置在GPU集群? _bilibili
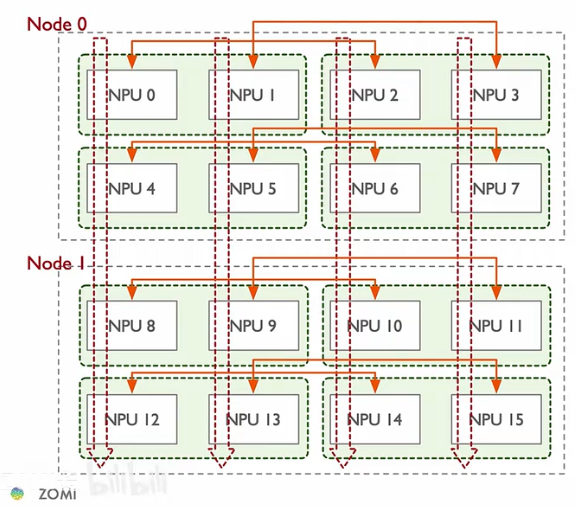
上图是一个PTD并行的例子。PTD分别表示流水,张量,数据并行。图中一共有两个机器节点,每个机器上有八个NPU,用rank来标识,比如NPU0,NPU1等等。
流水并行和张量并行需要切分模型,我们先看这两种并行方式是如何切分模型以及通讯的。
图中向下的红色虚线箭头表示一个流水并行通讯组,模型的不同层沿着这个虚线切分。它们之间以点对点的方式进行通讯。
绿色框框起来的是张量并行通信组,表示模型的相同层被切分到两个NPU上了。它们之间以集合通信的方式通信,也就是一次前向传播和反向传播all-reduce两次,一般放在单节点内,通过nvlink之类的方法在NPU之间直接通信。
图的左半部分组成一个完整的模型,右半部分复制了左边的模型,进行数据并行。对应位置的NPU通过集合通信来通信(橙色箭头)。通过ZeRO,可以将优化状态在左右两边分开存储。
(怎样分配比较好呢?是要看传输数据的时延是否能被掩藏吗?还是要考虑显存?脑子有点乱。比如上面的流水并行,不同stage之间的通信延迟不同,是不是会有影响呢?
数据并行的通信来自梯度同步+参数发送,这应该没法掩盖,张量并行的通信来自前向反向传播的all-reduce也不好掩盖,所以放在同一节点里是合理的
哎,这些问题别人肯定写了)
todo
单机多卡高速互联(延迟一般多大?):张量并行
多机器间并行(延迟一般多大?):流水并行,数据并行
单机显卡间互联拓扑
多机间互联拓扑
猛猿:图解大模型系列之:张量模型并行,Megatron-LM
猛猿:图解大模型系列之:Megatron源码解读1,分布式环境初始化
猛猿:图解大模型训练之:Megatron源码解读2,模型并行
猛猿:图解大模型训练系列之:Megatron源码解读3,分布式混合精度训练
猛猿:图解大模型训练系列之:DeepSpeed-Megatron MoE并行训练(原理篇)
猛猿:图解大模型训练系列之:DeepSpeed-Megatron MoE并行训练(源码解读篇)
从啥也不会到DeepSpeed————一篇大模型分布式训练的学习过程总结 - 知乎
ZeRO-Infinity
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
拆解一下字节的烧钱工作,MegaScale! - 知乎
细节好多todo
Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
Reducing Activation Recomputation in Large Transformer Model - 2205.05198.pdf
Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning | USENIX
Alpa - 算子内和算子间的自动并行
性能指标
hardware FLOPs utilization (HFU)
ratio of FLOPs observed on a given device to its theoretical peak FLOPs.
硬件利用率依赖于系统和实现,而且根据模型的不同而有所不同,和具体训练算法的实现(比如gradient checkpoint用重新计算换内存空间)也有关。同时直接估计FLOPs,不同的方法也会有不同的结果。
最终的目标是希望模型训练时对token的整体吞吐量变大,而不是提升硬件利用率。基于这个观察PaLM: 2204.02311提出了下面的指标MFU。
MFU模型算力利用率(Model FLOPs Utilization)
We propose a new metric for efficiency that is implementation-independent and permits a cleaner comparison of system efficiency, called model FLOPs utilization (MFU). This is the ratio of the observed throughput (tokens-per-second) relative to the theoretical maximum throughput of a system operating at peak FLOPs. Crucially, the “theoretical maximum” throughput only accounts for the required operations to compute the forward+backward passes, and not rematerialization. MFU therefore allows fair comparisons between training runs on different systems, as the numerator is simply the observed tokens-per-second, and the denominator is only dependent on the model architecture and published maximum FLOPs for a given system.
MFU = 实际每秒能处理多少token/机器理论上能处理多少token = 实际每秒能处理多少token/(机器理论峰值算力FLOPS/模型训练时平均每个token要的FLOPs)
= 实际每秒能处理多少token * 模型训练时理论上平均每个token要的FLOPs / 机器理论峰值算力FLOPS
也就是从模型这观测到的FLOPS/机器理论峰值FLOPS
其中模型训练时平均每个token要的FLOPs只和模型本身有关,不考虑gradient checkpoint(重计算)等方法增加的额外计算量。
模型训练时理论上平均每个token要的FLOPs 依据估算方法不同,结果也不同。比如有些方法不考虑自注意力的计算开销。
所以如果想要提升MFU,其实可以故意把模型训练时理论上平均每个token需要的FLOPs估大一点(
更详细的计算见PaLM: 2204.02311附录B
(FLOPS = floatpoint operation per second, FLOPs = floatpoint operations, 但也有人混用)
分布式训练框架
Ray 分布式ML计算
专门的分布式训练库
DeepSpeed
Megatron-LM
Colassal-ai
机器学习系统书 https://openmlsys.github.io