We illustrate this approach by converging transformer based models up to 8.3 billion parameters using 512 GPUs. We sustain 15.1 PetaFLOPs across the entire application with 76% scaling efficiency when compared to a strong single GPU baseline that sustains 39 TeraFLOPs, which is 30% of peak FLOPs.(指标:集群scaling efficiency, 单GPU利用率(对比理论FLOPs峰值))
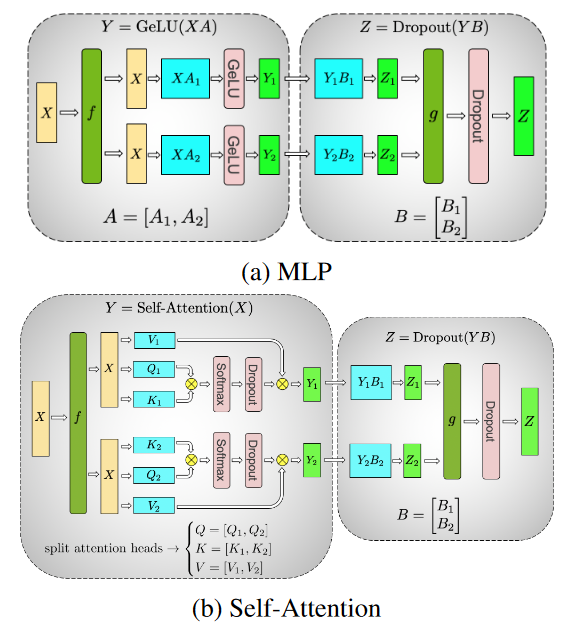
MLP
图a中X行batch维度,列是隐藏层维度。不考虑激活函数的话,这个MLP相当于两次矩阵乘法XAB。张量并行把A按列,B按行切分到不同设备上。
这样我们就只需要在X乘A的时候把X分配到对应设备上(f),然后再对应设备上继续乘完B后,将对应的Z1,Z2相加(g)
图中的f操作
前向:identity
反向:
图中的g操作:
前向:
反向:identity
也就是说,如果每层被横着切开,需要两次all-reduce,并且似乎无法被掩盖。每次all-reduce的通信量为中间激活的大小
多头注意力
图b的self-attention看起来有点乱,但也容易理解,因为本来multi-head self-attention里的multi-head就是把QKV竖着切开来分别算注意力。
最后在输入输出的时候,词表可能大小上万。因此也在输入输出时在词表维度做了切分,这里自己没有实践,也不是重点,也就不细看了。
张量并行属于模型并行,就是将一份模型的数据分开放。这样各部分的参数各自根据梯度更新自己的优化器,不用像数据并行要传梯度数据。
每一层传播需要交换数据,令N为每一层张量并行所分片的GPU数量,计算每一层每个GPU需要和别人通信