Dynamic-Batching
把数据送到模型里进行推理时,最好一次性送一个batch的数据进去处理。这样可以增加整体的计算强度和吞吐量。但是输入数据往往大小(长度)不固定,数据大小不固定的话就不能一个batch直接送进去了。
以坐大巴的比喻,Dynamic-batching就是凑够一波就走,凑不够的话,等够时间了也走。在应用过程中,需要设定最大batch_size,极限等待时间max_queue_time。
dynamic-batching是一种经典的batching方案,组batch之后计算任务就固定了,是ResNet、BERT在线服务提取特征这种应用场景的标准组件。
dynamic-batching的实现也比较简单,服务侧维护一个task-queue。batcher持续的从task-queue中弹出任务加入到working_set中,当working_set填满则立马发送到执行引擎中,如果task-queue为空则等待,如果等待超时且working-set不为空则发送执行引擎,如果working-set为空,说明服务整体处于idle状态,则继续等待。
Continous-batching

LLM推理分为两个阶段,预填充阶段和自回归推理阶段。预填充阶段如果要组batch,需要序列长度相同。自回归推理阶段则不需要,序列长度可以不同。
自回归推理阶段是输入一个token,然后计算它的qkv(与序列长度无关),计算注意力(与序列长度有关,但是batch中每个数据之间相互独立),然后计算MLP(与序列长度无关)。因此序列长度可以不同。预填充阶段和自回归推理阶段的区别在于,输入序列长度不为1,注意力计算不同,通过调整也是可以和自回归推理阶段的请求组batch的。
详见下面这个论文的讲解视频
Orca: A Distributed Serving System for Transformer-Based Generative Models | USENIX
interation-level scheduling,每执行一次推理就看看有没有序列结束了,结束了就调度另一个序列进来组成一个batch。
selective batching:阶段不同(自回归推理阶段或者预填充阶段)、长度不同的请求序列,都可以组成一个batch。不同请求在计算qkv时需要还原成各自的shape。
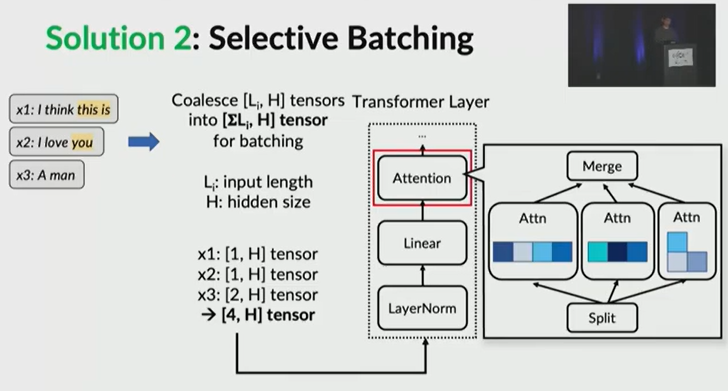
Plenty of following approaches inherit the selective-batching and iteration-level scheduling policy, such as continuous batching in vLLM and RayLLM [27] and in-flight batching in TensorRT-LLM [25].
提升batch size是增大延迟换吞吐,但是当batch size大到一定程度,吞吐提升就不明显了。因此可能需要设置一个最大batch size.