动机
最简单的kv-cache内存管理是提前分配一块连续的内存空间。然后随着推理的进行逐步填充。但是因为序列的推理长度不确定,可能用不满,这就产生了internal fragmentation。即使在未来能够用满,但是有相当长的一段时间这些内存都处于保留状态不可用(reserved)。可能序列长度过长,需要重新分配内存,但是因为external fragmentation的存在,无法放下一整段kv-cache。
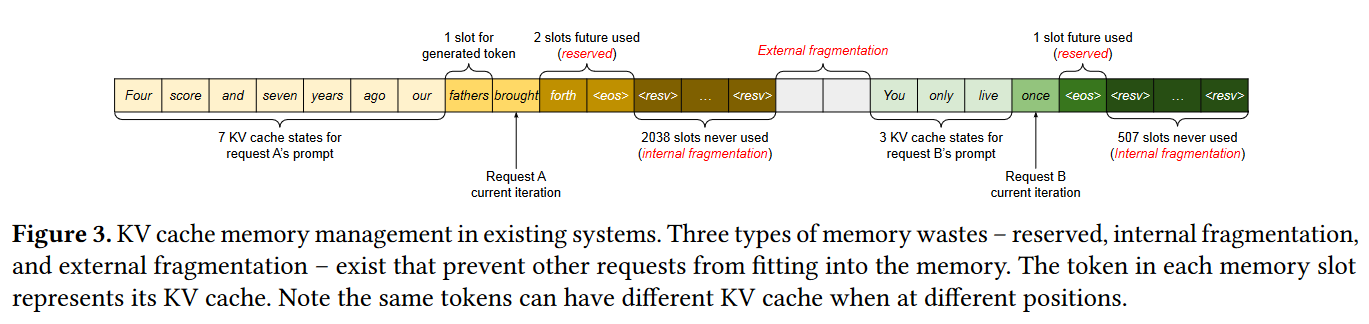
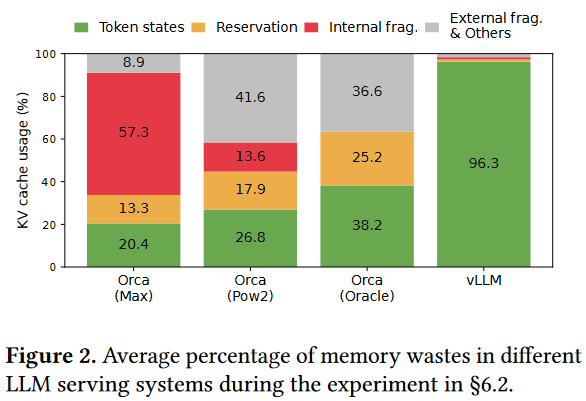
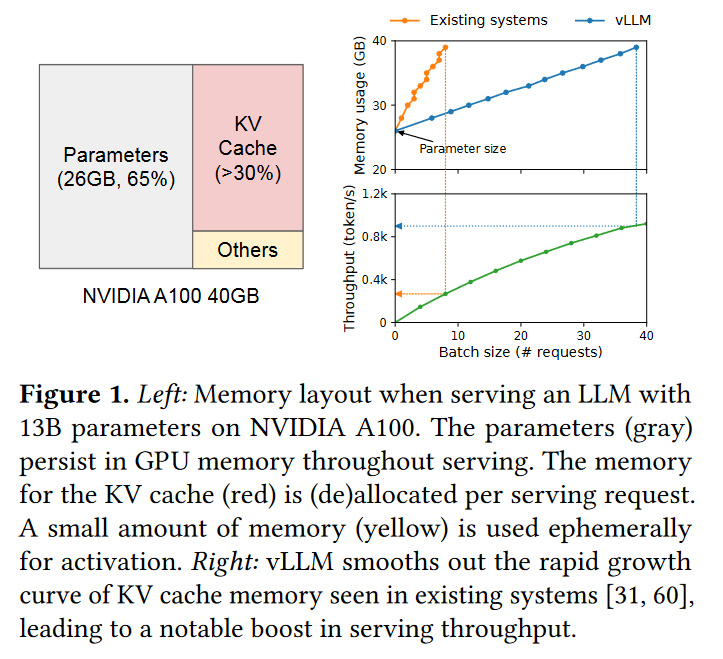
于是本文提出了PagedAttention来管理kv-cache的内存。这大大提升了内存的利用效率,从而让一张显卡上的batch size更大,从而增加吞吐。
算法
分页kv-cache
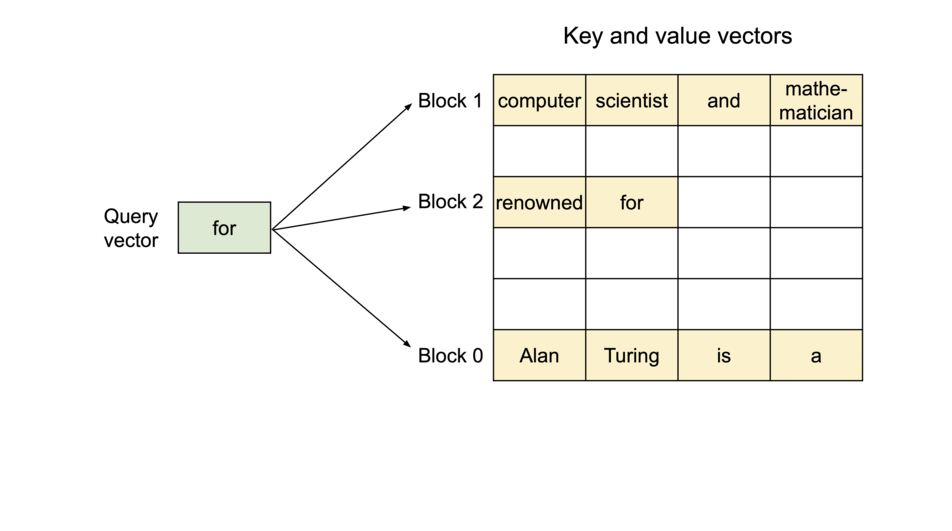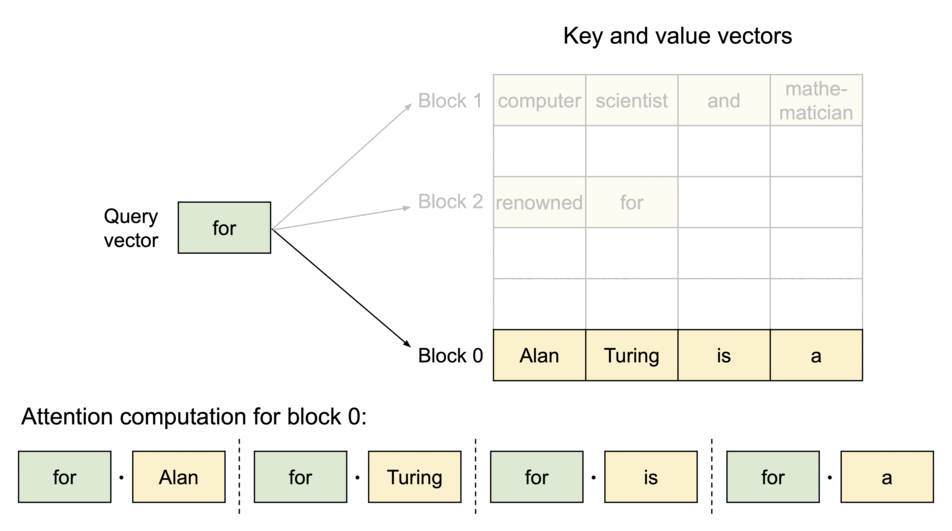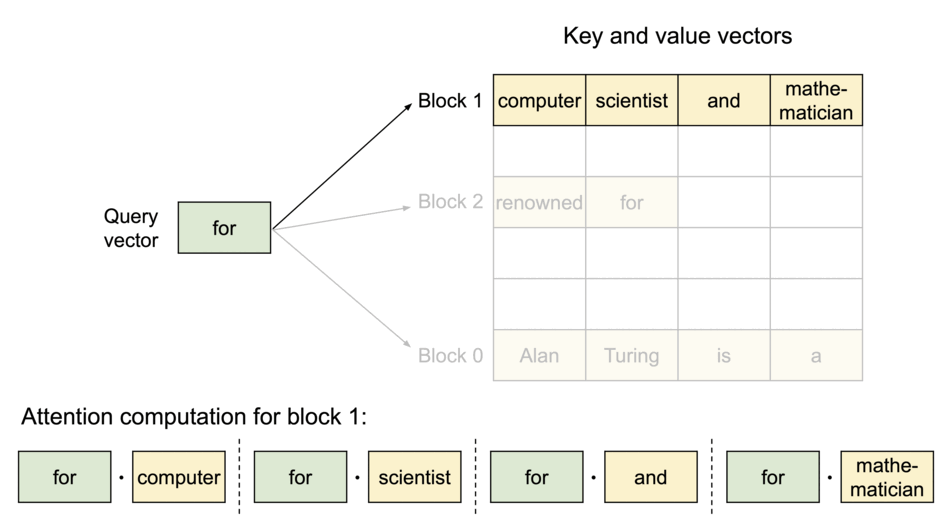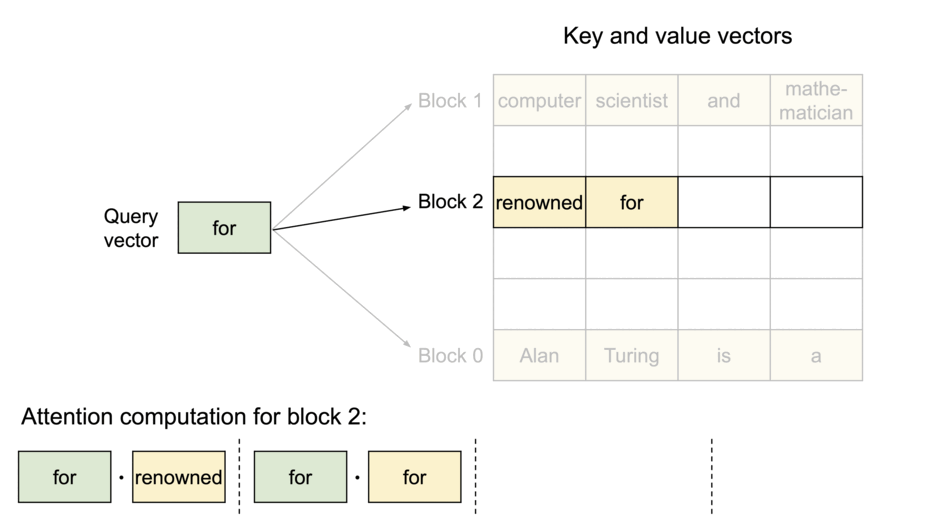
PagedAttention: 每个序列的KV Cache 被分成多个block,block不需要在内存中连续。计算注意力的时候分block计算。
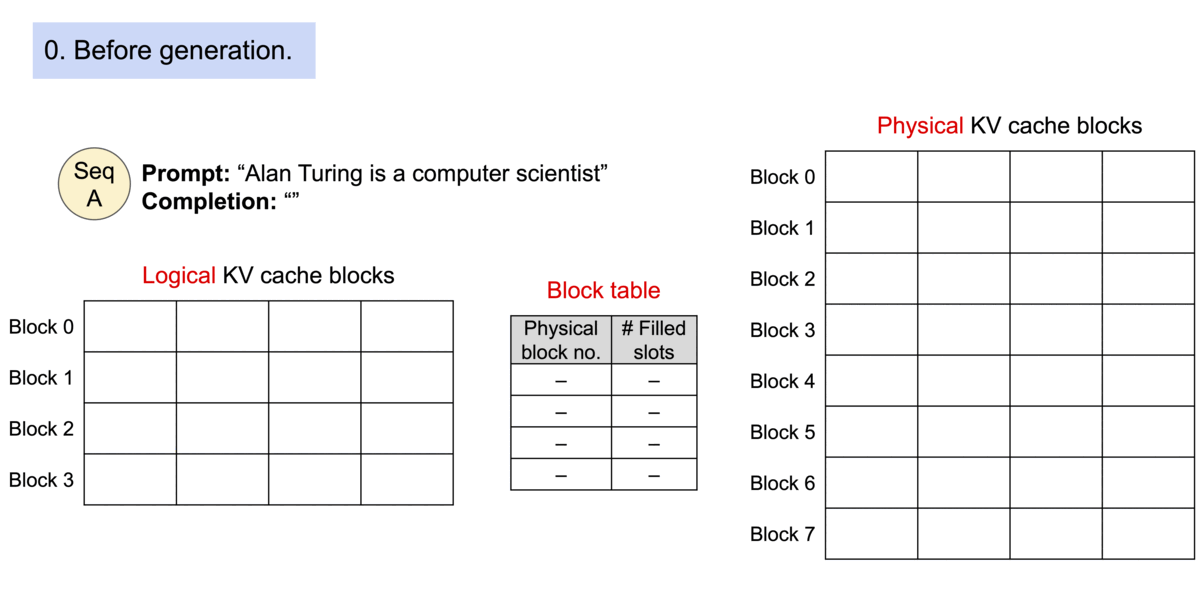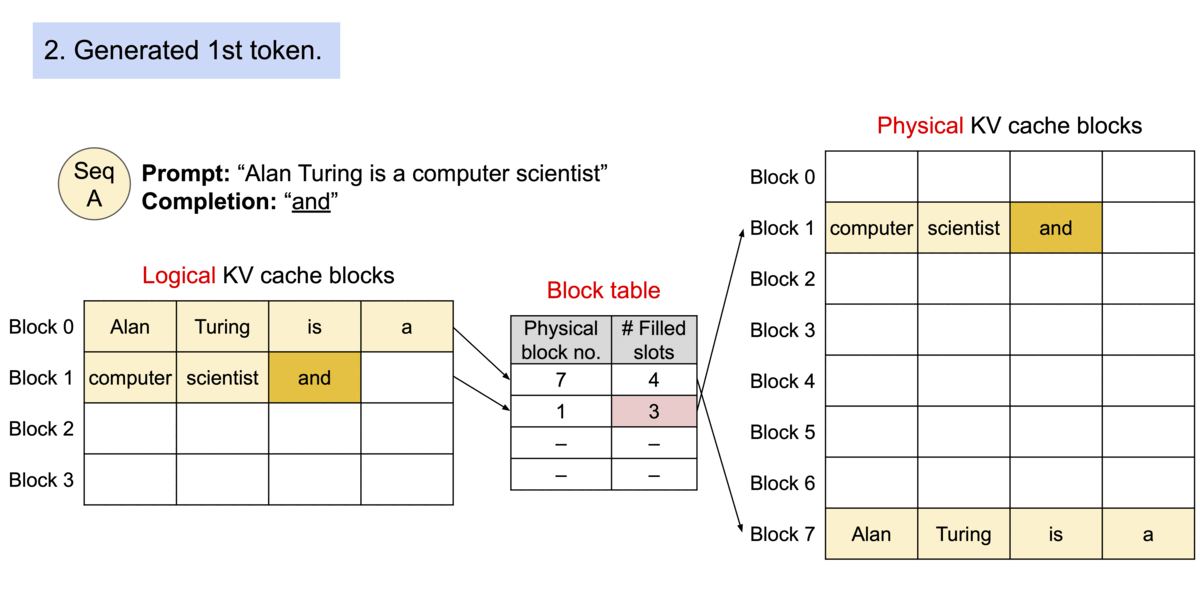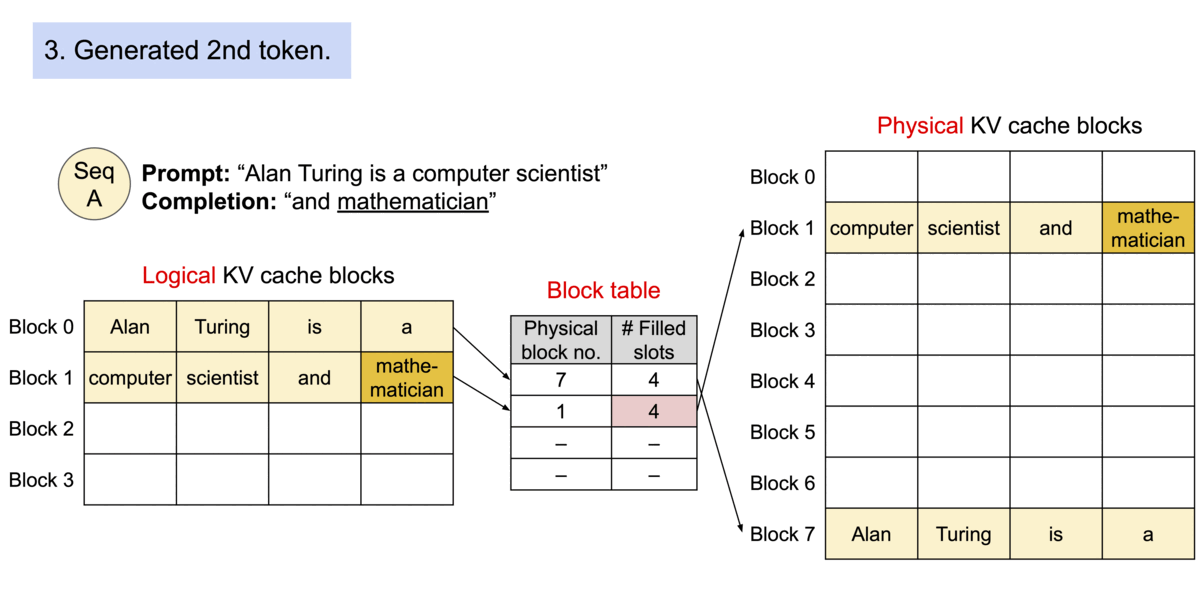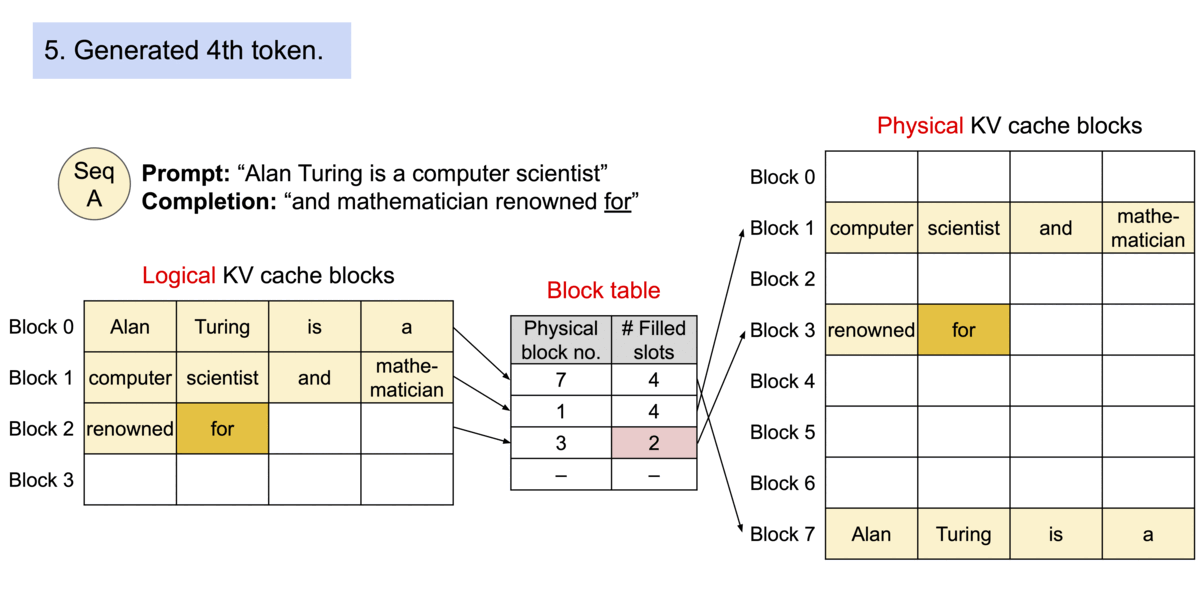
序列的kv-cache在逻辑上连续,但通过block table映射到不连续的物理block段上。
类比操作系统的内存分页:Because the blocks do not need to be contiguous in memory, we can manage the keys and values in a more flexible way as in OS’s virtual memory: one can think of blocks as pages, tokens as bytes, and sequences as processes.
既然block可以类比成虚拟内存的页表,那么当然也可以共享分页内存+写时复制,也可以方便的把暂时用不到的block换出到cpu内存上。
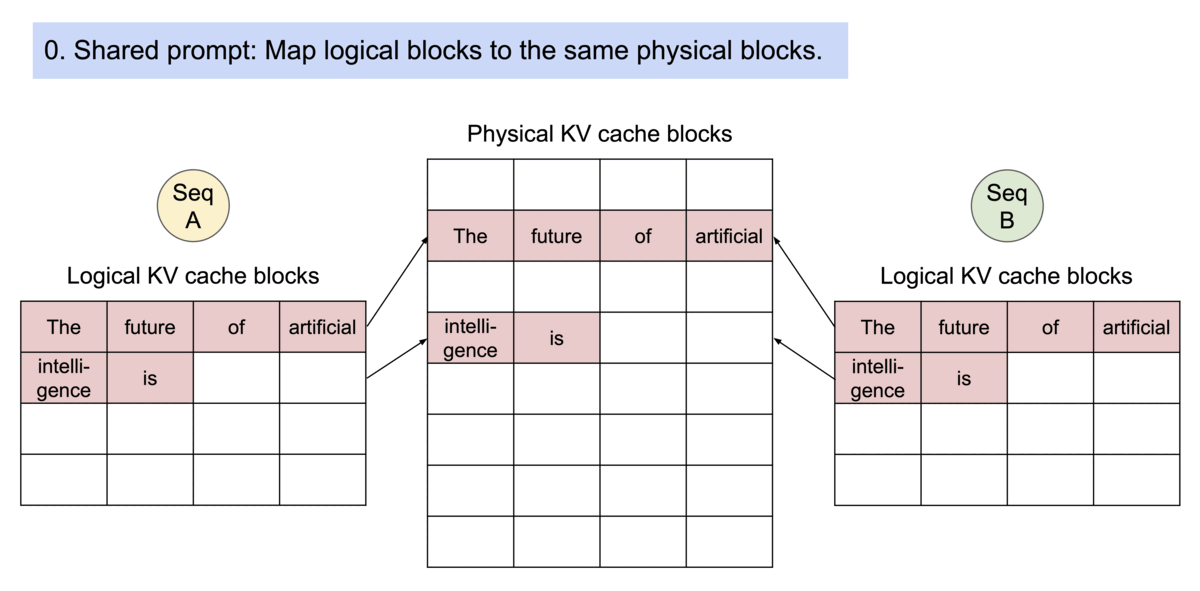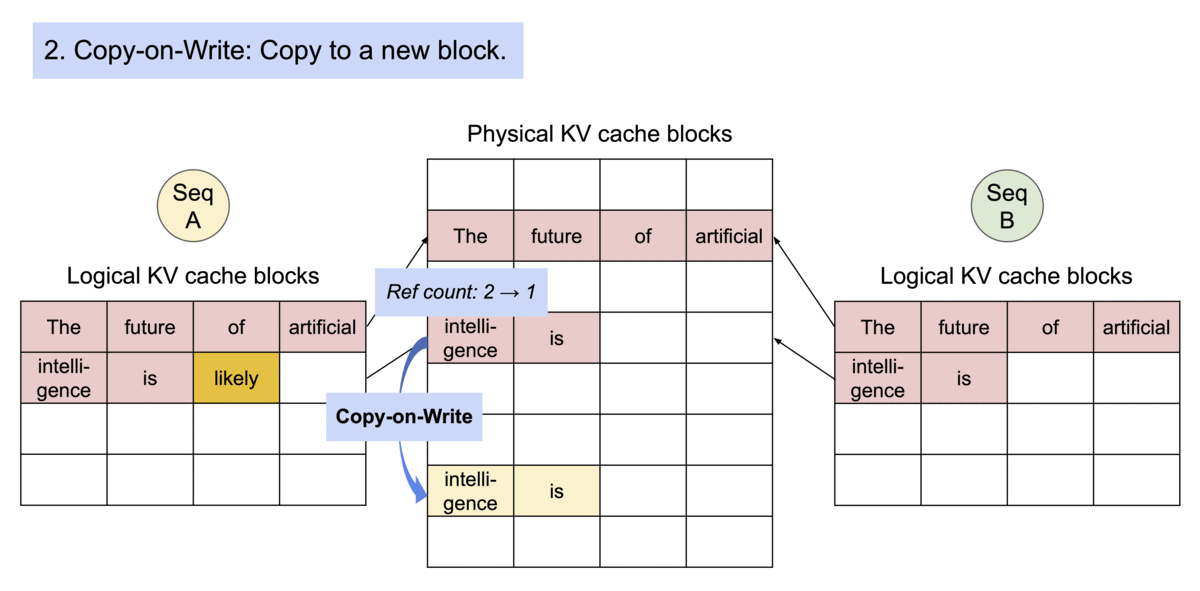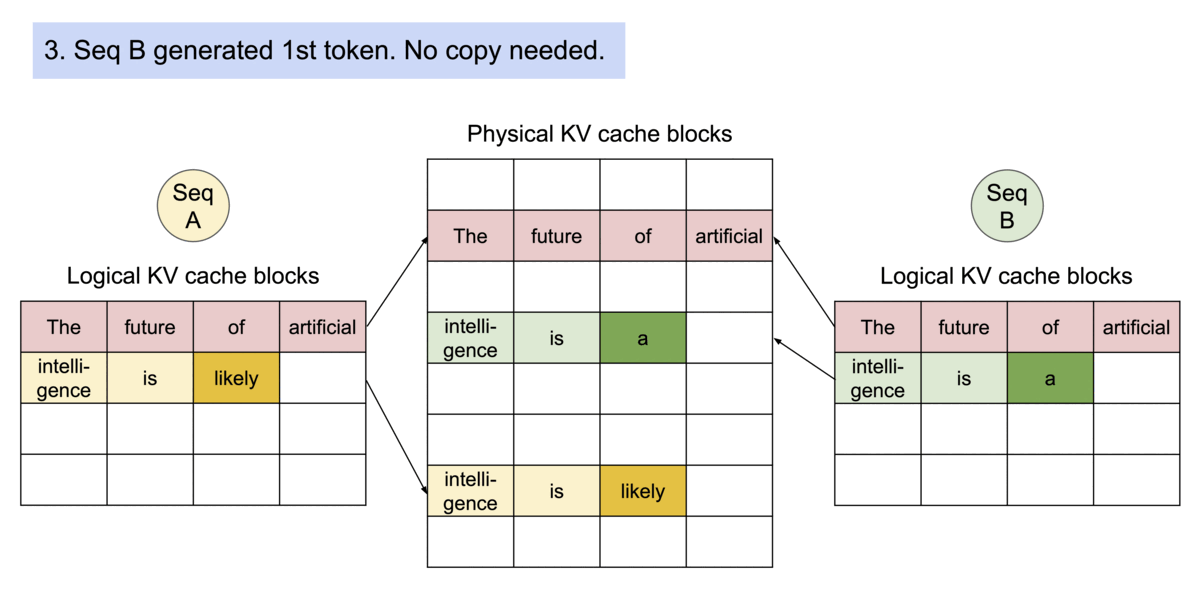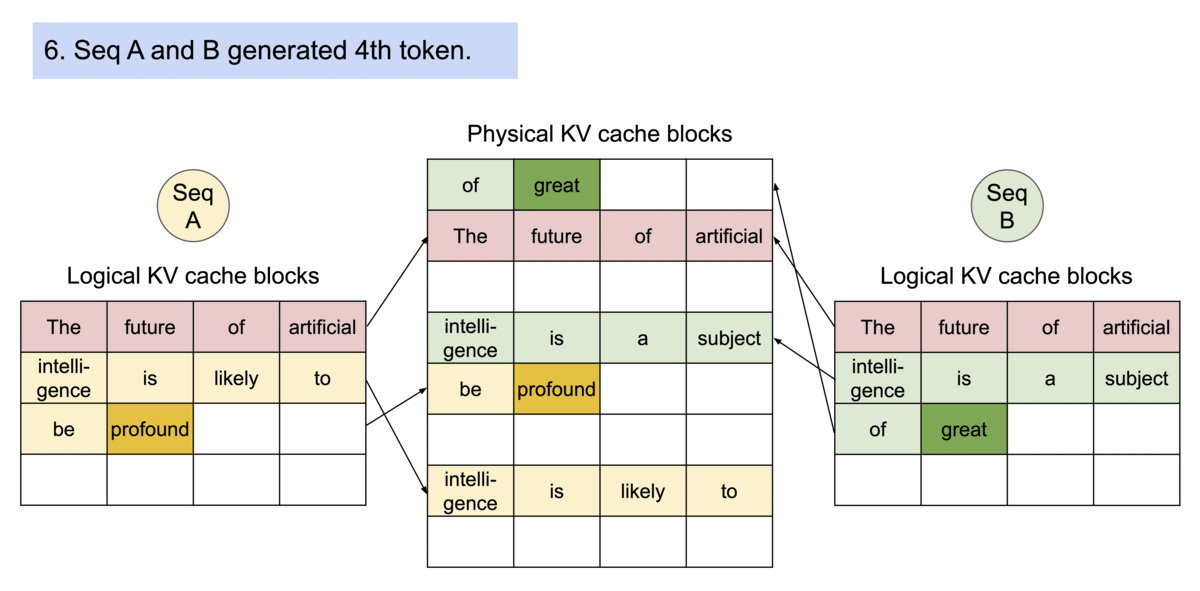
对同一个请求,采样不同输出。图中序列A和序列B都共享同样的kv-cache,因此它们的逻辑block可以映射到相同的物理内存上。
注意力计算
其他问题
当显存被kv-cache占满的时候,是把某个序列的kv-cache换出到cpu内存好,还是直接删除kv-cache,下个batch要用到时再重新计算比较好?
block大小取多少比较好?物理地址的不连续是否会降低gpu访存效率?