投机解码
这篇文章写的非常好,但是自己看完还是有疑问。于是看了deepmind的这篇论文。
[2302.01318] Accelerating Large Language Model Decoding with Speculative Sampling
动机:
自回归的大模型每次只能生成一个token,由于模型参数太多,生成单个token的时间最短也是模型参数/内存带宽。作者发现生成一次生成一个token和多个token所消耗的时间差不多,于是就想通过小模型先猜测出K个token,然后让大模型通过一次前向推理输出这K个token(和K+1个token)的logits,接着通过拒绝采样来让采样出来的结果和大模型逐个生成的结果分布相同。
分析:
作者主要是对Megatron那样使用张量并行来解码的Transformer来分析的
- 线性层:在向前计算的时候会通过很多线性层,都是对大矩阵的乘法。batchsize比较小的时候,都是memory bound,速度受内存带宽限制。K小的时候,依然是memory bound的,所以对时延影响不大。也就是这一部分一次预测多几个token耗时差不多
- 注意力机制:在推理时,需要对大量的KV-cache做注意力计算,这是是memory bound的。
- All-reduces:在Megatron的张量并行里,需要在MLP层和self-attention层后面做all-reduce,将各个gpu上的激活向量结果求和。因为每个token对应的激活向量数据量不大,一般是latency bound的。
(顺便,总时延=latency+数据量/带宽。latency取决于信号的传播速度,latency bound是说后一项比前一项小太多。在gpu内,latency可以通过一些技巧来隐藏。)

算法逻辑在伪代码里已经看的非常清楚了,但是不清楚的是为什么这样做”拒绝采样“就能让投机采样的采样结果和正常采样一样。
拒绝采样小知识:
我想要从q(x)中采样,但是实际上我只能从p(x)分布中采样。我设置一个M,使得q(x)<M*p(x). 这样我每次只要在分布p(x)采样到一个样本x1,然后按照q(x)/(M*p(x))的概率接受这个样本,就能间接的从q(x)中采样了。
过程是
- 从p(x)中采样x1
- 然后以
的概率接受。否则丢弃,这样在单次采样的时候,得到x1的概率就是 . 代价就是采样效率会变低为原来的1/M,如果M设置成2,那么你要采样两次才能得到原来在q(x)中采样一次的结果
之所以要,是为了在实际操作中有拒绝的余地,也就是M*p(x)要把q(x)包住
Modified Rejection Sampling
这篇文章里说的是 Modified Rejection Sampling
过程是
- 从p(x)中采样x1
- 如果q(x1)>p(x1),也就是大模型比模型还认同,就接受。否则以
的概率接受,以 的概率拒绝。 - 拒绝后在q(x)>p(x)的部分按照比例重新采样
详细可以看一眼证明,但是其实可以这样直观的理解:
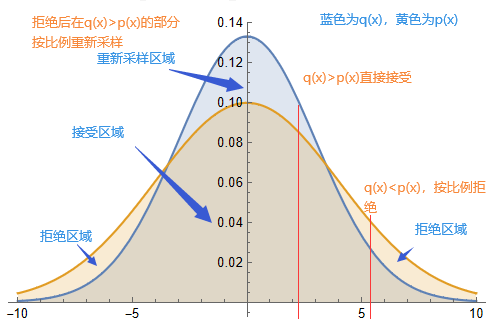
通过拒绝后在q(x)>p(x)的部分重新采样,我们相当于把两个分布之间不同部分的概率质量,从p(x)>q(x)的部分,搬移到了q(x)>p(x)的部分
同时也可以看出,每个token被拒绝的概率取决于q(x)>p(x)分布下的面积。因此想要高效的投机解码,还是要两个模型产生的分布尽可能相似。
普通的拒绝采样和本文提出的 Modified Rejection Sampling 有什么区别呢?普通的拒绝采样只有拒绝,和从参考分布p(x)采样的两部分,针对的是更通用的情况,是因为自己采样能力不行,所以才只能通过拒绝调整概率密度的形状。本文从p(x)和
回顾与分析
假定小模型推理一个token的时延为m,大模型推理一个token的时延为M,一次推理K个token的时延为M’。让小模型一次提前推理K个token,然后让大模型验证。假定每个token以p的概率被接受,以1-p的概率进入重采样。那么,进行一次推理的时延为,Km+M’. 一次推理推理出来的期望token数为Kp+1。
平均推理一个token的时延为,(Km+M’)/(Kp+1). K越大,单位token的推理时延越小,越趋近于m/p. 同时时延的方差也越大。所以需要根据实际情况设置
另一方面,将推理分成小模型猜测和大模型验证两个阶段,或许可以让整个过程流水线化,平均时延可以进一步隐藏。或者说给小模型再整个小小模型来投机解码(套娃是吧?),不过可不知道效果如何咯。
其他
以下主要是对这篇文章总结部分的补充和发散
并行解码方案拓展阅读
Speculative Decoding的遗憾在于需要额外再训练一个小模型(我觉得…其实挺好?)
粗看了以下方案流程,基本遵从生成+检查的组合(确实,当然要检查。除非在训练大模型一开始就考虑到解码速度的问题并做了改进。自己曾想过在大模型本来应该输出token的地方输出embedding,然后将embedding给小的预训练的解码器进行解码…但效果怎样真不好说吧)
- 并行解码(Parallel Decoding):Blockwise Parallel Decoding for Deep Autoregressive Models
- 美杜莎 Medusa:SpecInfer: Accelerating Generative Large Language Model Serving with Speculative Inference and Token Tree Verification
- [2310.07177] Online Speculative Decoding
- 和本文的的投机解码一样。用空闲的算力在线的用最新的查询数据训练小模型,以降低拒绝采样率。
- 前向解码LookAhead Decoding:与投机解码不同,不需要小模型,以集成在llama.cpp
- Break the Sequential Dependency of LLM Inference Using Lookahead Decoding | LMSYS Org
- gif图倒是很直观,让人不禁想问就这样缓存n-gram真的能加速解码吗?后面的画的注意力矩阵又让人非常迷惑,不知道在干啥。看代码,看的发晕,就不能给个伪代码/最简示例代码嘛…
Speculative Decoding总结
- 传闻ChatGPT推理技术会接近speculative decoding,这里的20B模型更像是蒸馏后的模型
- 对于投机解码,你以为是在玩并行解码技巧,实质是要求做出高质量的模型压缩工作(精度要求),才能有较高的accept rate
- Speculative Decoding里的大小模型的架构其实不够优雅,真正需要的是One-Model来“并行解码”推理
- 对于LLM推理玩家,除了研究KV Cache/显存管理/量化蒸馏,还需要再关注并行解码的技术
- llama.cpp工程集成了多种解码方式,感兴趣的朋友进一步深入吧。