维特比算法已经至少学了两次,忘了两次了。本科学的通信,这都不会有点说不过去。事不过三,这次写点东西记录一下
原理
假设我有三个隐藏状态a,b,c,并且知道它们的先验概率P(a),P(b),P(c),知道它们的转移概率P(a|b),P(a|c),P(b|c)等等
我还知道在每个状态a,b,c,它们都会以给定概率分别输出0或者1字符,输出概率为P(1|a),P(0|a),P(1|b),P(0|b),P(1|c),P(0|c)
图示如下,其中每条实线表示隐藏状态之间的转移概率,虚线表示它们输出01的概率。
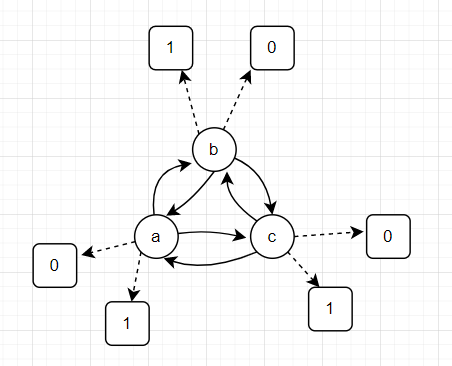
a,b,c三个状态之间的转移概率仅仅依赖于前一个状态,因此隐藏状态序列abcbc的出现概率为P(abcbc)=P(a)P(b|a)P(c|b)P(b|c)P(c|b)
这种概率模型叫马尔科夫链。
如果a,b,c三个状态是隐藏状态,我们只能看到它们以某种概率输出可见状态,而且输出可见状态的概率仅仅取决于当前的隐藏状态,那这就是隐马尔可夫模型。
给定输出概率(或者叫发射概率)、转移概率,和a,b,c自身先验的出现概率,这个隐马尔科夫模型就确定了。维特比算法想解决的问题是,如果看到一个可见状态序列,那么它对应的最大可能的隐藏状态序列是什么?
假设我对可见序列一无所知,那么隐藏状态序列abcbc的出现概率为P(abcbc)=P(a)P(b|a)P(c|b)P(b|c)P(c|b)
可见序列为00011,同时隐藏状态为abcbc的联合概率为
P(abcbc , 00011)=P(a)P(b|a)P(c|b)P(b|c)P(c|b)P(0|a)P(0|b)P(0|c)P(1|b)P(1|c)
那么在观测到可见序列为00011的条件下,隐藏状态为abcbc的条件概率为
P(abcbc | 00011)=P(abcbc , 00011)/P(00011)
而给定隐马尔可夫模型,观测序列的概率P(00011)就是确定的。因此,在观测到00011的情况下,求让条件概率P(S | 00011)最大的S,等于是求让联合概率P(S , 00011)最大的S
顺便,因为给定了转移概率,所有可能的隐藏状态序列P(S)是确定的。因为给定了输出概率,P(00011|S)也是确定的。
现在问题就是怎么高效的求出来让联合概率P(S , 00011)最大的序列S
P(abcbc , 00011)=P(a)P(b|a)P(c|b)P(b|c)P(c|b)P(0|a)P(0|b)P(0|c)P(1|b)P(1|c)
上述概率可以画图如下
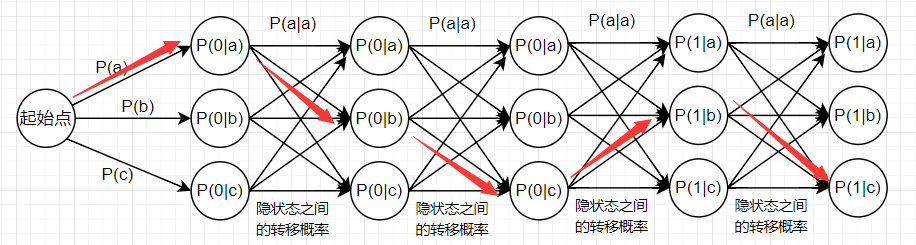
其中,隐藏状态之间的每一条边指的是隐藏状态之间的转移概率,每个节点指的是该状态输出对应可见状态的条件概率。上面想要最大化的联合概率,在图中表示为对应隐藏状态的路径。因此只需要找到概率乘积最大的路径即可,通过动态规划,可以在O(N)时间里算出概率最大的路径,N为序列长度。
在使用动态规划进行计算的时候,会需要打表。这里细说一下表里数字的物理意义
trellis矩阵 行为隐藏状态数,列为序列长度 trellis(s, t)表示0~t的联合概率
比如上图中红色箭头的第二个节点里,对应的打表存的应该是从起始点到当前节点的概率乘积,也就是P(ab , 01),再后面一个节点打表时存的应该是P(abc , 000)
希望概率的乘积最大,在取负对数后,就变成了希望打分的和最大。这里的打分,指的是对应概率的负对数。
因为是希望找到图中得分最大的路径,那么反过来也是一样,所以维特比算法也有反向的版本。
代码实现
import numpy as np
# Define the HMM parameters
states = ['A', 'B', 'C'] # possible states
observations = ['o1', 'o2', 'o3'] # possible observations
transition_matrix = np.array([ # 转移概率矩阵P(上一个隐藏状态,下一个隐藏状态)
[0.7, 0.2, 0.1], # transition probabilities from state A
[0.3, 0.5, 0.2], # transition probabilities from state B
[0.1, 0.3, 0.6] # transition probabilities from state C
])
emission_matrix = np.array([ # 发射概率 P(隐藏状态,发射可见状态的概率)
[0.4, 0.3, 0.3],
[0.2, 0.4, 0.4],
[0.3, 0.2, 0.5]
])
prior_probabilities = np.array([0.4, 0.3, 0.3]) # prior probabilities of the hidden states
# Define the observation sequence
observation_sequence = ['o1', 'o2', 'o3', 'o1', 'o2']
# Initialize the trellis 行为隐藏状态数,列为序列长度 trellis[s, t]表示第t个隐藏状态为s的概率
trellis = np.zeros((len(states), len(observation_sequence)))
# Forward pass
for t, o in enumerate(observation_sequence):
for s in range(len(states)):
if t == 0:
trellis[s, t] = emission_matrix[s, observations.index(o)] * prior_probabilities[s] # 第一个隐藏状态s输出o的概率
else:
trellis[s, t] = max([trellis[prev_s, t-1] * transition_matrix[prev_s, s] * emission_matrix[s, observations.index(o)]
for prev_s in range(len(states))]) # 第t个隐藏状态s输出o的最大概率
# Backward pass
viterbi_path = np.zeros(len(observation_sequence), dtype=int)
viterbi_path[-1] = np.argmax(trellis[:, -1]) # 正确隐藏状态序列的最后一个
for t in range(len(observation_sequence)-2, -1, -1): # 往回找前一个状态,这里的s就对应前向计算时的prev_s。所以也可以在前向计算时不在trellis保存概率,而是只保存前一个状态的指针
viterbi_path[t] = np.argmax([trellis[s, t] * transition_matrix[s, viterbi_path[t+1]] for s in range(len(states))])
# Print the Viterbi path
print("Viterbi path:", [states[i] for i in viterbi_path])import numpy as np
# Define the HMM parameters
states = ['A', 'B', 'C'] # possible states
observations = ['o1', 'o2', 'o3'] # possible observations
transition_matrix = np.array([ # 转移概率矩阵P(上一个隐藏状态,下一个隐藏状态)
[0.7, 0.2, 0.1], # transition probabilities from state A
[0.3, 0.5, 0.2], # transition probabilities from state B
[0.1, 0.3, 0.6] # transition probabilities from state C
])
emission_matrix = np.array([ # 发射概率 P(隐藏状态,发射可见状态的概率)
[0.4, 0.3, 0.3],
[0.2, 0.4, 0.4],
[0.3, 0.2, 0.5]
])
prior_probabilities = np.array([0.4, 0.3, 0.3]) # prior probabilities of the hidden states
# Define the observation sequence
observation_sequence = ['o1', 'o2', 'o3', 'o1', 'o2']
# Initialize the trellis 行为隐藏状态数,列为序列长度 trellis[s, t]表示第t个隐藏状态为s时,前一个隐藏状态是啥
trellis = np.zeros((len(states), len(observation_sequence)), dtype=int)
joint_p = np.zeros(len(states))
o = observation_sequence[0]
for s in range(len(states)):
joint_p[s] = emission_matrix[s, observations.index(o)] * prior_probabilities[s] # 第一个隐藏状态s输出o的概率
# Forward pass
for t, o in enumerate(observation_sequence[1:], start=1):
new_joint_p = np.zeros(len(states))
for s in range(len(states)):
tmp = [joint_p[prev_s] * transition_matrix[prev_s, s] * emission_matrix[s, observations.index(o)]
for prev_s in range(len(states))] # 找第t个隐藏状态s输出o的最大概率
new_joint_p[s] = max(tmp)
trellis[s, t] = tmp.index(new_joint_p[s]) # 记录这个最大概率的上一个状态
joint_p = new_joint_p
# Backward pass
viterbi_path = np.zeros(len(observation_sequence), dtype=int)
viterbi_path[-1] = np.argmax(joint_p) # 正确隐藏状态序列的最后一个
for t in range(len(observation_sequence)-2, -1, -1): # 往回找前一个状态,这里的s就对应前向计算时的prev_s。所以也可以在前向计算时不保存概率,而是只保存前一个状态的指针
viterbi_path[t] = trellis[s, viterbi_path[t+1]]
# Print the Viterbi path
print("Viterbi path:", [states[i] for i in viterbi_path])好长,以后这种代码是不是放到github gist上,然后引用一个链接会更好(