Muzero:
- 作者给了python伪代码,可以先看伪代码,再看下面博客的解读
- 原作者博客
- MuZero Intuition 自己的翻译 Muzero的直观理解
- Muzero unplugged Online and Offline Reinforcement Learning by Planning with a Learned Model
- 尝试完全不与环境交互,直接对已有轨迹数据重分析
- Efficient zero Mastering Atari Games with Limited Data
- 在Muzero上做了一些改动,大大提升数据利用效率
- 使用SimSiam风格的损失对隐藏状态的表示向量做了一些对齐。
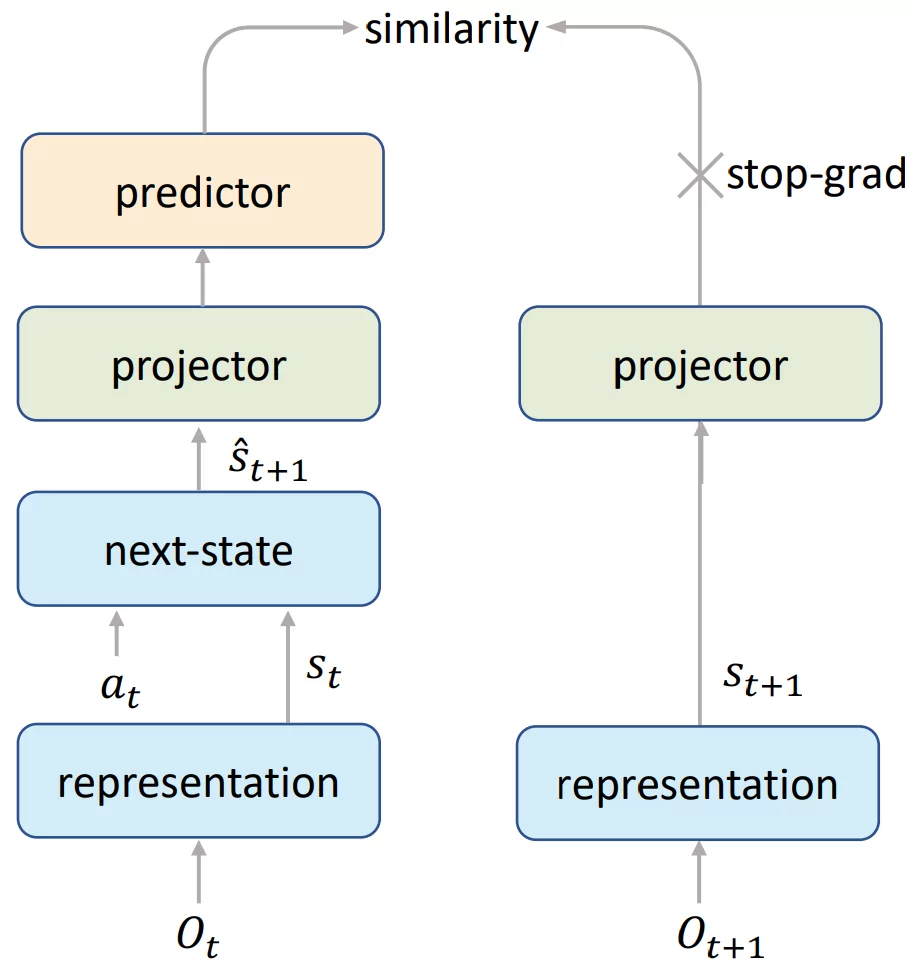
- End-To-End Prediction of the Value Prefix
- 改进Muzero的重分析,修改旧轨迹的TD steps (没懂)
- Sampled Muzero Learning and Planning in Complex Action Spaces
- 代码复现
之所以看AlphaGo及其后续的工作,主要是注意到LLM是一个序列决策问题,可能可以通过MTCS等强化学习的方法来提升输出的可靠性。当前LLM的rlhf等其实都只是提升单步输出的效果。
Muzero训练了一个dynamic model,这个动态函数g根据当前的动作从当前状态向量映射到下一个状态向量。这就让模型可以在隐藏空间进行计划。大家都在说世界模型,这种能在隐藏状态空间中根据动作预测下一个隐藏状态的模型才是世界模型吧?
在Efficient zero里,对前一步和后一步的隐藏状态表示做了一些对齐。这其实很像于JEPA,就是JEPA不能做动作,只能是用相邻的环境无监督预训练而已。但有一点不太了解,就是JEPA里随机向量Z是怎么选的。
除了MuZero系列工作,应该还有别的有趣的工作。应该都可以结合起来,可是自己没精力仔细看和复现啊…要毕业,要找工作了
Reinforcement Learning Upside Down: Don’t Predict Rewards — Just Map Them to Actions - YouTube
- 从
变成 ,好处是可以利用结果不太好/奖励不高的训练轨迹进行训练
Dreamer v2: Mastering Atari with Discrete World Models (Machine Learning Research Paper Explained) - YouTube - 先训练世界模型,然后用它做规划
几个问题:
- MTCS可以用于连续动作空间吗?
- Sampled Muzero好像是通过在连续动作空间采样几个离散动作,然后优化。改改应该是可以的
- 除了两个玩家交替对抗的情况,MTCS可以用于单个玩家或者多个玩家吗?
- 单个玩家应该可以。MuZero does YouTube 设计的对抗游戏里似乎就是单个玩家的游戏。但是仍然通过某种方式和过去的自己竞争。
其它改进
一个对muzero的改良,去除了MCTS
Muesli: MuZero without MCTS. Achieving MuZero’s state-of-the-art… | by Aznaur Aliev | Medium
如何选择深度强化学习算法?MuZero/SAC/PPO/TD3/DDPG/DQN/等(2021-04) - 知乎
- 看了上面几篇应该对MuZero有了初步认识,把这种基于蒙特卡洛树搜索的强化学习方法应用到语言模型上似乎也很直接。下面是一些工作
对LLM来说,要学关于环境的奖励函数。
self-play
Dota 2 with Large Scale Deep Reinforcement Learning - openai | 1912.06680.pdf
MCTS + RL 系列技术博客(6):浅析 MCTS 算法原理演进史 - DILab决策实验室的文章 - 知乎
https://zhuanlan.zhihu.com/p/670885213