简单的讲解和好看的gif图 GitHub - cybertronai/gradient-checkpointing: Make huge neural nets fit in memory
详细的讲解 Fitting larger networks into memory. | by Yaroslav Bulatov | TensorFlow | Medium
论文 1604.06174.pdf
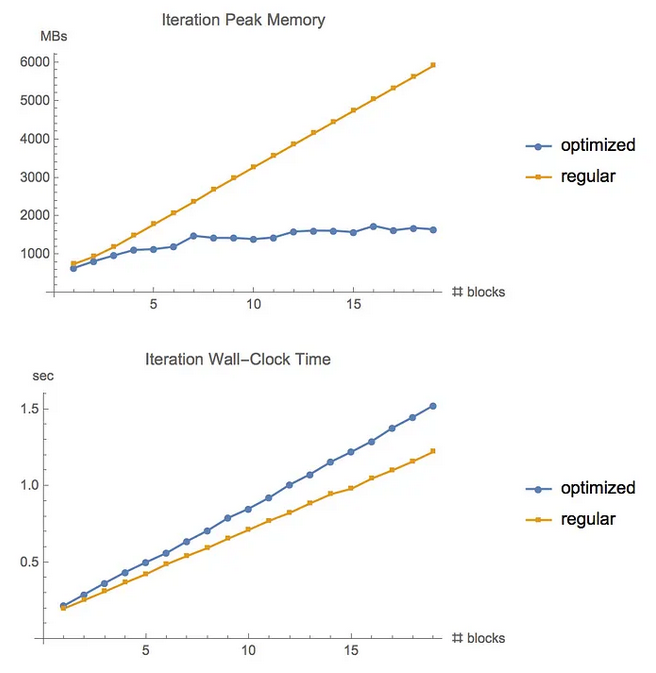
这是一种用计算换存储空间的方法。写这个的起因主要是自己看Gpipe时想分析一下到底用额外用多少计算换回来多少存储空间。
深度学习的神经网络往往由很多层组成,在前向传播的时候,每层都需要保留一些激活值来方便在反向传播的时候通过链式法则计算梯度。因此,这些激活值所占的内存在前向传播的时候会增加,反向传播的时候会变小。由于每层都要保留激活值,这部分动态内存随神经网络层数的增加线性增长,也就是
下面可以看到通过增加固定比例的运算时间,可以大幅降低峰值内存。
For feed-forward models we were able to fit more than 10x larger models onto our GPU, at only a 20% increase in computation time.
算法原理
前向与反向计算图
任何计算都可以写成计算图的形式。计算图由数据节点和算子节点组成。算子节点接受几个算子节点的输入,然后将输出作为几个新的数据节点,然后新的数据节点又作为其他算子节点的输入。算子节点想要计算,作为输入的数据节点的值就必须已经算出来了,这种依赖导致前后相连的计算图是有向无环图。
(在网上有很多关于计算图的示意图,有些把数据节点省略并标注在边上,有的把算子节点省略并和输出节点合并,我觉得都有误导性,因为也没人规定一个算子只能输出一个数据节点/一个数据节点只能被用一次)
神经网络的前向计算图也是这种有向无环图。通过链式法则,我们可以求出每个输入节点相对于最终的某个输出节点的梯度。
在教学链式法则时,往往会对着前向计算图来讲解。相对于某输出的梯度按照前向计算时相反的顺序(逆拓扑序)沿着计算节点反向的流回去,并且每次乘上该算子的局部梯度。(
但是其实这里隐含了另一张计算图,反向计算图。算梯度的时候也是计算,所以当然有反向计算图。反向计算图一般自动生成。在没有被特殊优化的时候,反向计算图的每个计算节点
比如
从这样的视角看,反向传播并没有特殊之处,梯度也只是数据节点。因此反向计算图和正向计算图其实可以整合到一起,成为一张完整的计算图。这样我只要输入当前批次的数据和参数,就可以在输出节点获得参数的梯度数据。
而正是因为反向计算图依赖于正向计算图的某些中间数据节点,这才需要在计算过程中存储额外的数据。
多层神经网络
下面这个图表示了一个多层神经网络计算图大概的样子。每个圆圈是数据节点
向右的计算步骤大概是
反向大概是
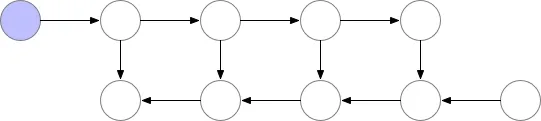
因为是多层,所以这种数据依赖的模式会导致中间存储节点正比于层数。
如果不想像上面缓存中间节点,就在每次用到的时候重新计算吧。
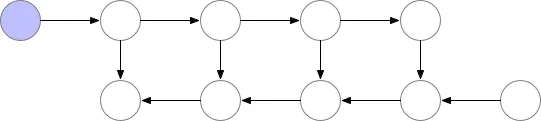
一个折中的策略是在中间选取几个checkpoint节点做保留,方便计算gradient。
那么怎么样选取checkpoint能在这种多层的情况下,在不增加计算复杂度的情况下(计算量还是增加的,计算复杂度和之前一样是
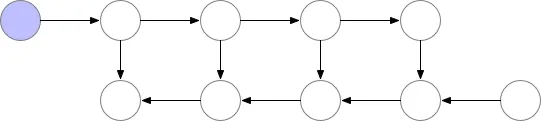
办法也很简单,就是每
这样就取得了一个计算复杂度和空间复杂度的平衡点。
但是有些神经网络并不是一层一层那么规整的,也就不好选checkpoint节点。
有些算子比较特殊,也需要具体情况具体分析。
如果看了还是不太清楚,或者想看看在更多种类的神经网络中如何checkpoint,可以看看这个。Fitting larger networks into memory. | by Yaroslav Bulatov | TensorFlow | Medium
增加了多少计算?
增加的计算量略小于一次完整的前向计算。
而反向传播的计算量/耗时大概是前向计算的两倍。 在训练神经网络时,反向传播为什么比正向传播慢很多? - 知乎
所以增加时间约为原先的1/3.
在GPipe中,因为重计算过程和反向传播无关,所以可以和通信重叠。图示如下
其它工作
[2406.16282] Reducing Fine-Tuning Memory Overhead by Approximate and Memory-Sharing Backpropagation
优化掉不必要的中间激活值,减少峰值占用显存
- 激活函数的激活值
- layernorm / rmsnorm 的激活值