今天看到这篇文章[2402.17764] The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits,光是看摘要就惊了一下。权重只要是-1,0,1就可以和相同参数量的全精度LLM效果相近?而且似乎是训练时量化??
性能方面,所有参数变成-1,0,1确实可能有相似的性能。如果把参数想象成旋钮,旋钮的数量比精度更重要。
直接训练一个低比特的神经网络肯定不行,每次估计的梯度更新无法体现在低精度上。因此可能需要全精度的优化器状态参数和模型参数来累积梯度,同时使用低比特的版本来前向传播。也就是混合精度训练里的方式。
如果在前向传播的时候把参数换成更低比特,比如-1,1会怎样呢?首先就是weight从fp32变成低精度时会有损失,精度过低,会导致fp32版本的权重更新了,但是低比特的没有更新,或者只有少量更新,这样训练出来的低比特网络好不好呢?难说,但是很值得试一试
另外一个问题就是梯度怎么估计?
想到这里忽然意识到,混合精度训练里节省训练显存、加速训练并不是主要目的,直接训练出一个低精度模型才是最重要的呀。
看看图
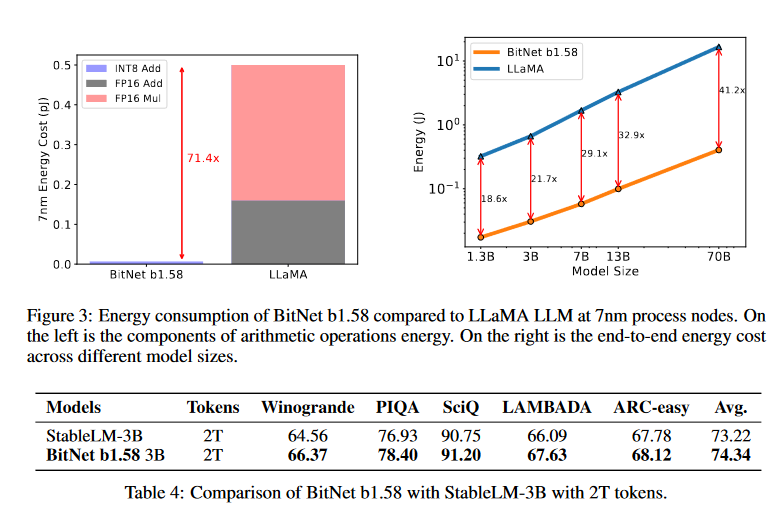
BitNet里每个参数为-1,1,所以是1bit。BitNet b1.58每个参数是-1,0,1,因此就是1.58bit。
下表比较了相同参数量下,BitNet b1.58和LLaMA的性能。
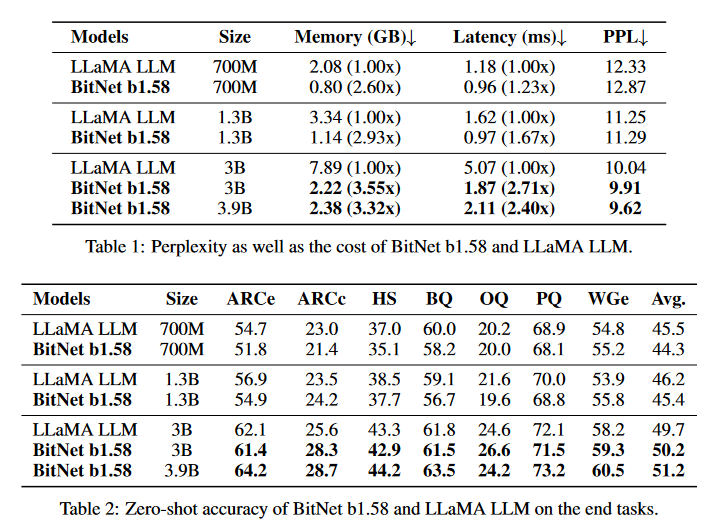
下面来看看原始的BitNet是怎么做的
BitNet论文记录
[2310.11453] BitNet: Scaling 1-bit Transformers for Large Language Models
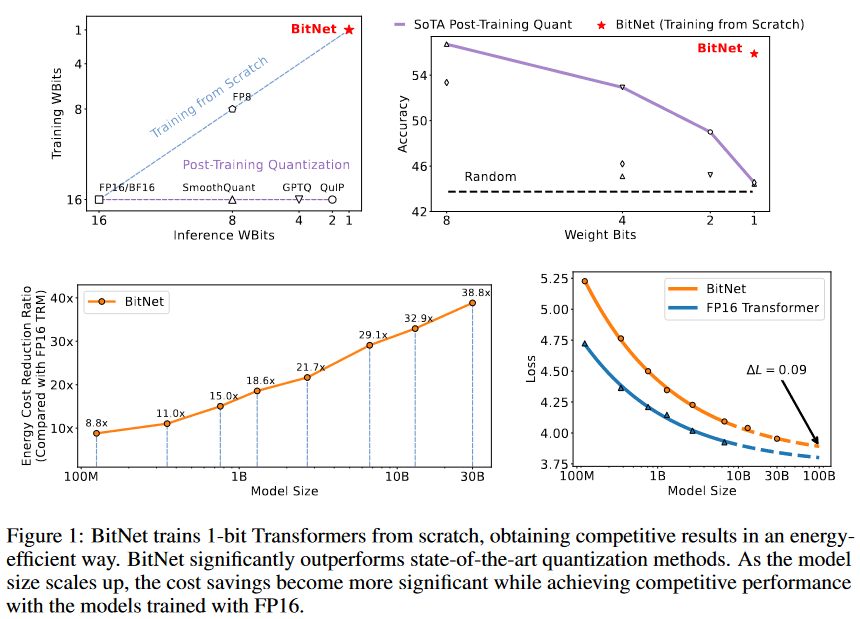
效果:
训练时和推理时是相同的精度,相较于Post-Training Quantization性能更好。相较于fp16 Transformer性能差的不远。
结构:
直接把Linear换成BitLinear就行
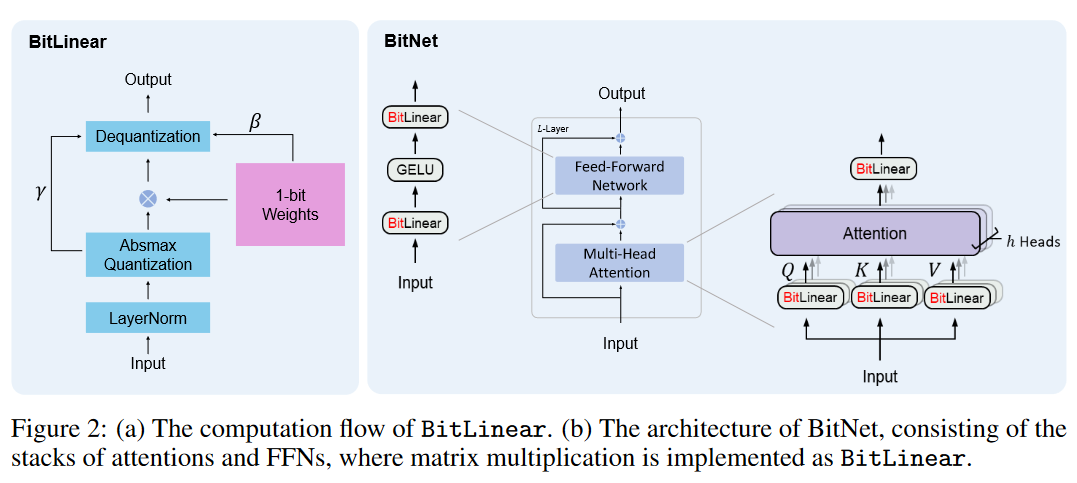
BitLinear
训练过程
更详细的训练时计算图如下
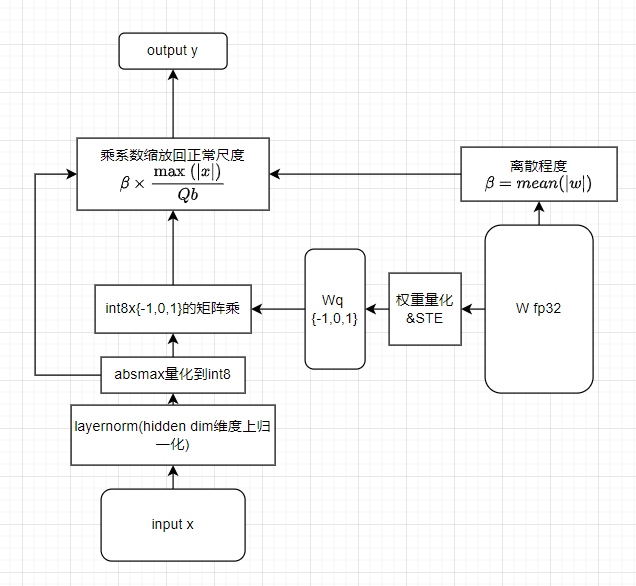
对图上的各个模块做个注解(符号和论文用的不太一样,因为两篇文章它自己的符号也不太一样)
- 输入x的维度为(batch size, seq len, hidden size),layernorm在最后一维做归一化得到x’。让它均值为0,方差为1
- 然后对归一化后的x’进行缩放,乘
,然后量化成int8(-128~127)。这里 - 训练时对tensor量化(就是对整个x算max(|x|)),推理时对token量化(就是对hidden size维度?)
- 将权重量化成{-1,0,1}
- 这里bitnet和bitnet b1.58的做法不一样,下面是b1.58的做法。
,然后 缩放后,量化到-1,0,1
- 然后把量化后的x和W进行矩阵乘,最后缩放回量化前的尺度。具体来说,对输出结果整体乘
,来让Wq和W更相近。对输出x在对应维度乘 (在哪个维度量化的就在哪个维度缩放回去) - STE(Straight-through estimator):量化时使用的是阶梯函数,没有导数。为了训练方便,在反向传播时认为导数是1. 为了训练稳定也可以对梯度做一些额外的其他的处理,比如截断。
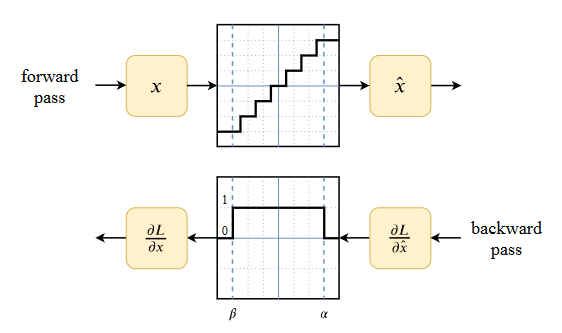
反向传播过程论文里没有详细说,这里按自己的理解瞎说一下:
BitLinear只是内部量化了,输入和输出的中间结果都是高精度的。反向传播的梯度也是高精度的浮点数。中间激活采用int8保存,也就是图中absmax量化后的结果,然后相乘得到激活和权重各自的梯度。
除了上面提到的东西,还有:
- 混合精度训练
- 相对于fp16混合精度训练更大的学习率
推理状态
推理时,计算图如下
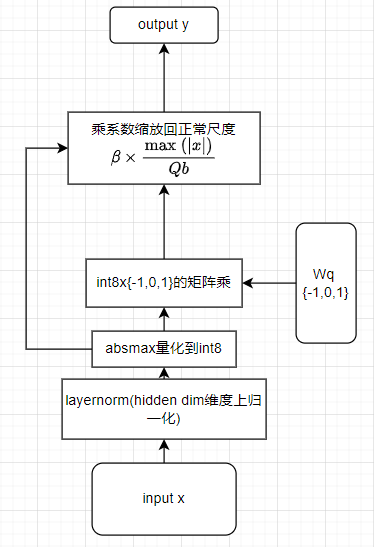
针对模型并行增加的修改
在每个binlinear里面,需要对线性层的所有权重计算均值,需要对x计算layernorm,需要对归一化的输入x计算max(|x|)。这就不方便模型并行。论文中对需要切分的权重和x进行了分组,每组计算各自的均值/max/layernorm。
示例代码
下面是自己当时试着复现的,当时看了看几个所谓的复现代码都有点奇奇怪怪的。在llama.c代码基础上改了改,在tinystorys数据集上试着训练了一个小语言模型。训完发现一个小模型也说明不了什么。
作者后来也在补充的faq里增加了代码和调参设置。
import torch
import torch.nn.functional as F
from torch import nn
class RoundClip(torch.autograd.Function):
@staticmethod
def forward(ctx, input, min, max):
return torch.clamp_(torch.round(input), min, max)
@staticmethod
def backward(ctx, grad_output):
# Straight-Through Estimator
# return F.hardtanh(grad_output)
return grad_output
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, weight: bool, eps: float):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim)) if weight else None
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
if self.weight:
return output * self.weight
else:
return output
class BitLinear_3b(nn.Module):
def __init__(self, in_features, out_features, activation_bits=8, eps=1e-5):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.activation_bits = activation_bits
self.activation_quant_scale = 2**(activation_bits-1) - 1 # -127 ~ 127
self.eps = eps # 防止除0
# Initialize weights
self.weight = nn.Parameter(torch.randn(in_features, out_features))
# parameters for quantization and dequantization
self.gamma = None # absmax of input activation , per layer 输入的每行都有自己的缩放系数
self.beta = None # absmean of weight matrix
def forward(self, input):
# 在最后一维进行归一化
input_norm = RMSNorm(input, weight=False, eps=self.eps)
# Absmax Quantization
self.gamma = torch.max(torch.abs(input_norm), dim=-1, keepdim=True) + self.eps # per layer
input_quant = RoundClip.apply(input_norm / self.gamma * self.activation_quant_scale, -self.activation_quant_scale, self.activation_quant_scale)
self.beta = torch.mean(torch.abs(self.weight)) + self.eps
# {-1,0,1} Weights Quantization
weight_quant = RoundClip.apply(self.weight/self.beta , -1, 1)
# Quantized MatMul
output = input_quant @ weight_quant
# Dequantization with learnable parameters
output = output * self.beta * self.gamma / self.activation_quant_scale
return output
class BitLinear_3b_learnable(nn.Module):
def __init__(self, in_features, out_features, activation_bits=8):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.activation_bits = activation_bits
self.activation_quant_scale = 2**(activation_bits-1) - 1 # -127 ~ 127
# Initialize weights
self.weight = nn.Parameter(torch.randn(in_features, out_features))
# learnable parameters for quantization and dequantization
self.gamma = nn.Parameter(torch.tensor(2)) # absmax of input activation # 假如输入在layernorm后是方差为1的正态分布,这里设置成2sigma
self.beta = nn.Parameter(self.weight.detach().abs().mean()) # absmean of weight matrix
def forward(self, input):
# 在最后一维进行归一化
input_norm = RMSNorm(input, weight=False, eps=self.eps)
# Absmax Quantization
# self.gamma = torch.max(torch.abs(input))
input_quant = RoundClip.apply(input_norm / self.gamma * self.activation_quant_scale, -self.activation_quant_scale, self.activation_quant_scale)
# self.beta = torch.mean(torch.abs(self.weight))
# {-1,0,1} Weights Quantization
weight_quant = RoundClip.apply(self.weight/self.beta, -1, 1)
# Quantized MatMul
output = input_quant @ weight_quant
# Dequantization with learnable parameters
output = output * self.beta * self.gamma / self.activation_quant_scale
return output
# 可修改的地方:
# 激活的量化的absmax或许可以改成可学习的,因为前一步本来就layernorm过了
# 权重量化的absmean可以改成可学习的。量化的时候可以选择改成对权重矩阵逐列量化。
BitLinear = BitLinear_3b相关文章
[2310.11453] BitNet: Scaling 1-bit Transformers for Large Language Models
[2402.17764] The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
unilm/bitnet/The-Era-of-1-bit-LLMs__Training_Tips_Code_FAQ.pdf at master · microsoft/unilm · GitHub
社区讨论
如何看待微软提出的BitNet b1.58? - 知乎
Reddit | The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Paper page - The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
草,几乎没啥区别的工作…
GitHub - ridgerchu/matmulfreellm: Implementation for MatMul-free LM.
二值化神经网络相关工作
自己之前对量化相关其实并不了解,下面只是粗略的记录一下这半天来看的东西。
直接训练一个低精度网络
其实直接训练一个二值化网络前人也研究过,但主要是针对CNN。
和本文关系最大的两篇
- XNOR-Net(和这个工作基本一样,只是针对cnn)
- XNOR-Net++
transformer的量化工作
和QAT(量化感知训练)的关系?
是通过插入伪量化节点在训练好的模型上微调/训练。
深度学习量化
其他
如果这篇工作的效果真如它所说的那么好,也能scale。那么在个人电脑上用本地的gpt4也许真的不是梦,期待一下。
- 利好DSA/fpga等等
- 模型推理一次,主要需要加载kv-cache和模型权重,现在权重是低比特量化的,就意味着加载kv-cache计算attention的时间会成为大头。意味着投机解码和attention方面的优化会更重要。
- 使用zero优化器训练时,发送模型权重的开销变少了
作者发了另一篇文章介绍训练细节,以及提到了在训练后期降低学习率时,perplexity会快速下降,因此训练中途的ppl并不具有代表性。
我是相信随着模型变大,直接训练的低比特和fp16模型之间的差距会越来越小。直接训练的低比特模型因为大部分都是整数矩阵乘,所以效率显然比目前主流的训练后再量化,将参数即时转换成fp16再矩阵乘的方案要快许多。
假如大部分模型都将线性层中的矩阵乘换成上面这个低比特版本来直接训练,会
不过将这种方法推广还是存在许多问题
- llama3使用了7倍于llama2的token数来训练。性能大大提升。而llama3同时也面临着量化后模型性能下降严重的问题。这就意味着,一般的大模型是没能经过充分训练的,也因此有足够的冗余对参数进行压缩。
- 反过来说,在小参数模型上训练更长的时间,是为了推理性价比(性能 / 推理开销)。那么如果用更大参数的低比特模型,是否在训练时能更快的收敛到给定ppl,同时推理时也可以更快呢?这里面应该存在权衡的空间
- llama3证明了高精度大模型一般没有被充分训练到收敛,那低比特的大模型训练到什么时候会收敛呢?收敛后的效果如何呢?
- ppl即使相同,能充分说明性能上的问题吗?
- bitlinear这种做法能够在其它应用场景使用吗?
- 基于fp16摸索出来的经验/方法可能不适用,或者需要修改
- Lora?
- 之前有人说模型融合可以获得不错的性能,非fp16的权重咋融合?