[2305.20050] Let’s Verify Step by Step阅读笔记
本文详细比较了结果奖励模型和过程奖励模型在加强数学推理能力上的效果。
过程奖励模型比结果奖励模型能更好的对推理过程做监督,因此能辅助llm生成更好的解答。
方法
研究范围
本文使用固定的generator来生成所有解答。文中的outcome/process supervision指的是对奖励模型监督训练的方式,不讨论对generator的监督。但是使用强化学习用奖励模型对generator进行调整是很自然的后续工作。
相反,我们专注于如何训练最可靠的奖励模型。我们通过对generator均匀采样的结果用奖励模型评分,然后用best-of-N结果的正确率来评估奖励模型。对于每个测试问题,我们选择奖励模型中排名最高的解答,根据其最终答案自动对其进行评分,并报告正确的部分。更可靠的奖励模型会更频繁地选择正确的解决方案。
Base Models
大模型使用GPT-4的base model
较小规模的模型在数学相关的数据集MathMix上预训练
Generator
使用few shot在MATH训练问题上生成目标格式的解答,然后过滤出答案正确的解答。
用上面的问答数据,在base model上微调一个epoch,目的是教模型生成想要的格式。
结果奖励模型
ORM细节
- 使用预训练的gpt
- 每个token都输出预测。预测的标签为整个推理解答是否正确。可以由人来标注,但是实际是直接检查答案是否正确来判断的,因此可能包含过程错误,但是结果正确的情况。
- 在中间步骤token输出的标签预测也是对整个推理解答是否正确的预测。
- 实际使用的时候,直接使用最后一个token的输出预测来判断整个推理解答是否正确。
PRM800K
一共收集了1085590个step级别的标签,一共有101599个解答样本。过滤掉有些labeler无法标注的情况后,剩下80 0000个step级别的标签和75000个解答样本。
数据收集分为两个阶段。第一阶段我们给解答的每一步都有多个替代的补全方案(?)
重复性更高。(就是直接拿生成的解答去让人标?)有40000个step标签。
第二阶段采用active learning来迭代的收集数据,一共收集了十轮。对每一轮,我们都用已有的所有数据训练一个当前最好的PRM。然后对每个问题,从generator里收集N个解答。接着使用最好的PRM对解答排序,依照分数从高到低,把高分的错误答案给labeler标注。标注到第一个出现错误的step就可以了。收集完数据后,重新训练一个更好的PRM,进行下一轮。
active learning收集的数据都是convincing wrong answer,但在出错之前,还是有大量的正确步骤。
第二阶段还有质量控制问题。在开始第二阶段之前,所有labeler都要标30个质量控制问题,然后移除标准答案有75%不一样的labeler
在每一轮,都设计了10-20个额外的质量控制问题,随机提供给labeler,删除标注质量太差的labeler的结果。还提供了教育材料和常见错误来帮助labeler和我们对齐。(有没有可能给出指南,让ai帮忙验证每个step啊)
过程奖励模型
整个解答过程被分成step,每个step之间通过换行分隔。
预测时,将整个解答过程输入gpt,每个step末尾的token都会输出当前step推理正确的概率。预测标签为positive, neutral, negative。在预测时,neutral可以是被视作正确也可以被视作错误。
只有当每一步都是正确的,整个解答过程才是正确的。为了给整个解答过程一个分数,可以考虑将每个step正确的概率相乘,这样只要有一步正确概率低,整体的正确概率就低。(这里作者在 PRM Detail - F.2 Scoring 比较了将neutral视为positive/negative,相乘/取最小情况下,奖励模型监督性能。)
step的奖励到底是什么
自己阅读的时候,有点不太理解每个step输出的正确概率究竟指的是什么。在参考了一些论文后,大体上有三种PRM:
- 指到目前为止所有step都正确的概率。
- 指当前step正确的概率。(什么是当前step正确?)
- 指从当前step往后rollout,有多大概率正确。即认为在解答结束的时候给奖励,正确为1,错误为0. 给出当前step的价值函数值
在训练PRM时,85%都是错误解答,错误解答只标到第一个错误就停止。那么怎么解释在这样的数据上训练出来的PRM呢?
观察论文里给出的错误示例,发现在第一个错误出现之后,后续的step还是有可能是正确的。所以PRM给出的应该是指当前step正确的概率。
那么它是如何评判当前step正确的概率呢?
一个理解方式是,PRM每次给当前step评分时,先查询上文中所有相关step,并检查这些step的内容是否有矛盾,如果有矛盾,当前step最正确的做法就是修正矛盾(比如提出解释,修复错误),如果没有矛盾(有可能有错,但是相关step里没有矛盾),就检查上文所有相关step是否能推出当前step。



论文的PRM输出的是当前step“所涉及的推理”正确的概率。
下面这张图中,红色表示当前step的推理错误,绿色表示当前step的推理正确,注意按照前面的理解,step5虽然基于step4的错误推理,但它这一步本身还是正确的,所以是绿色的。这样所有step相乘,就代表整个解答过程中所有推理都正确的概率。
如果按照1的理解,step5就应该是红色,因为它的父步骤step4是错的。此时PRM的最后一个step输出的概率就是整个解答过程正确的概率。
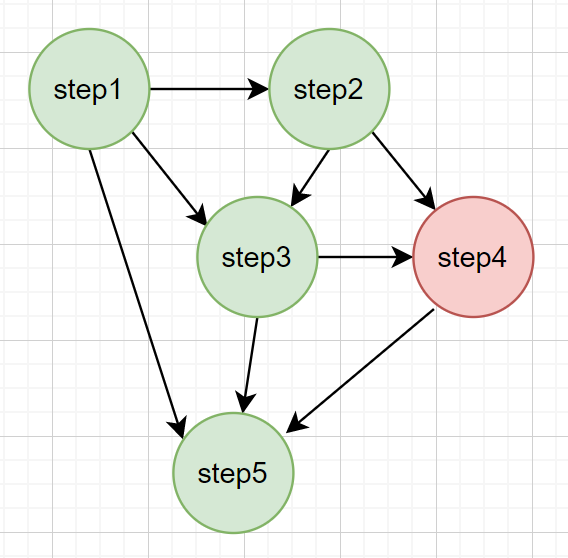
3的理解则和1,2完全不一样。1,2是往前看,客观的判断当前step的概率,不管前文是什么模型生成的,对就是对,不对就是不对。而3是对未来的预测,每个step指的是从当前step,按照语言模型采样,往后生成到正确结果的概率。这种PRM类似于alphago里的价值函数,它其实是在估计往后赢棋的概率。它是依赖于策略函数的。如果按照这种理解去做过程奖励模型,也许就可以用MTCS对step来估计价值。
事实上[2408.03314] Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters就是这样理解的。它说verify step by step发布的PRM800K数据集调出来的PRM,无法很好的分辨正确步骤,容易被骗。它自己按照MCTS估计了每一步的价值,按照这种方式训练了个PRM。
第三种做PRM的方式的好处是可能可以引导模型生成有效/有进展的step,不至于说是说一堆正确的废话。坏处是价值函数是和策略函数相关的,往后生成step的模型不同,它所认为的某步step所具有的value也不同。
一千个人眼中有一千个哈姆雷特。在能自我纠错的o1和初始的gpt3.5眼中,即使是相同的上文,能生成正确结果的概率也完全不同。因此这样弄出来的PRM也不一样,但是相同的上文中,问题解决了多少,当前步骤是否正确,都是客观的。
另一个坏处是,它要求问题有可以容易验证的最终答案,然而在大部分领域是没有的。
alphago是在封闭的棋盘世界里,通过outcome supervise(即最终游戏是否赢了),来训练的。因此用MCTS+价值函数是比较合理的。但是面对开放世界的各种问题,我们往往没有最终答案,因此PRM通过验证每一步推理过程来实现process supervise才更合理。我们凭什么相信一个数学证明正确?因为它是“推理步骤”正确的。可靠的推理能力是一种客观的基本能力,它不是价值函数。价值函数是想要估测之后会发生什么,结局会得到什么奖励,并且将它的预估浓缩成价值,推理能力是确认当前step和前面的step关系是否正确。这种价值函数即使能在数学领域判断哪一步价值高,我怀疑也不一定能在物理领域判断哪一步价值高,即泛化性差。而仅仅验证当前step推理是否正确就容易很多。
另外,价值函数并不是人类反馈训练出来的reward model。它给价值估计,而不是reward。真正的PRM应该是对了一步有一步的奖励,所谓“怕什么真理无穷,进一步有进一步的欢喜“。只要推理过程是正确的,即使无法达成目标,中间构建的二级结论对其它问题也是有用的呀。
再比如说模型能从自己无意间说的一句看起来是废话的地方得到顿悟/启发…而且很多情况下思考会陷入一个死胡同,然后顿悟,这样也许就很难估计某步的价值了。反过来说,如果能很好的对这种价值进行估计,问题不就解决了吗?很多东西,只有回过头来反思,才能意识到重要性呀。
(本来看Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters是想看看它是怎么scale test time compute的。抱怨一下,对这个工作最不满的地方就是它连PRM每一步的奖励到底是什么都没理清,在scale test time compute的方法都没有成熟的前提下,就谈论如何optimal的scale,有啥意义嘛)
实际过程奖励模型中输出step的概率打分到底是什么,应该取决于数据标注方式,以及奖励模型怎么理解这些数据。这些其实可以训练完之后测试出来。
其它论文
[2312.08935] Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
这篇论文对奖励模型的理解和verify step by step一样。它将中间步骤step1的质量定义为某个语言模型从step1开始往后生成正确最终答案的潜力。然后自动收集分步监督。
问题在于,这样生成的监督数据有很多噪声。而且效果严重依赖于用什么语言模型生成解答步骤,比如一个有纠错能力的语言模型和一个会累积错误的模型显然不同。它是一种”向后看“的标注方法。比起这种方法,对每个step通过prompt让最好的语言模型验证正确性来自动化标注可能更好。
作者还说使用了step-by-step ppo来训练,但并好像没有细说训练方法,只是给了结果。自己也没找到代码。在另一个工作GitHub - deepseek-ai/DeepSeek-Math: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models里,4.1.3. Process Supervision RL with GRPO提到,每个token的优势函数(或者说奖励)是当前步骤加上所有后面步骤的奖励。这可能不太对,每个token的优势函数(或者说奖励)应该是当前步骤奖励,不包含后续步骤的奖励。从直觉上看,后面的推理对不对,和当前步骤一点关系没有。step-by-step强化学习的目标不是最大化序列奖励,而是孤立的看待每个step,最大化每个step的奖励。step level ppo
PRM数据标注
- 过程奖励模型训练数据
- 推理过程生成:使用few shot在预训练的gpt上生成
- 推理过程打标签
- 雇人对推理步骤打标签。
- active learning:不断的收集convincing wrong answer. 这种回答奖励模型无法分辨是否正确,但是人可以通过某种方式得知它是错误的(比如根据最终结果判断正误,或者错误步骤本身就是人类生成的)。然后标注错误步骤,作为训练数据。
- 其它可能的收集wrong answer的脑洞
- 让模型生成正确步骤,但是故意在其中添加微妙的错误步骤?(比如抄写错误,计算错误,逻辑错误等等…)
- 每一步通过prompt来问模型是否有问题,或者作为辅助标注人员的备选项…
- 将大量已知正确的解题过程,让语言模型格式化一下,然后插入错误。
- 生成大量简单的逻辑推理问题,让语言模型重写成比较自然的形式,再插入错误
- 等等等等
- true positive, true negtive
给标注人员看的数据标注标准:PRM800K标注指南
在大模型上用标注数据训练奖励模型
PRM:用PRM800K训练
ORM:每个问题采样100个回答,以结果是否正确为标签
注:虽然两个奖励模型的训练集不能直接比较,但这都是作者在两种奖励模型能训练最好的结果。下一节会用大奖励模型替代人类来监督训练小的奖励模型,以此进行比较。
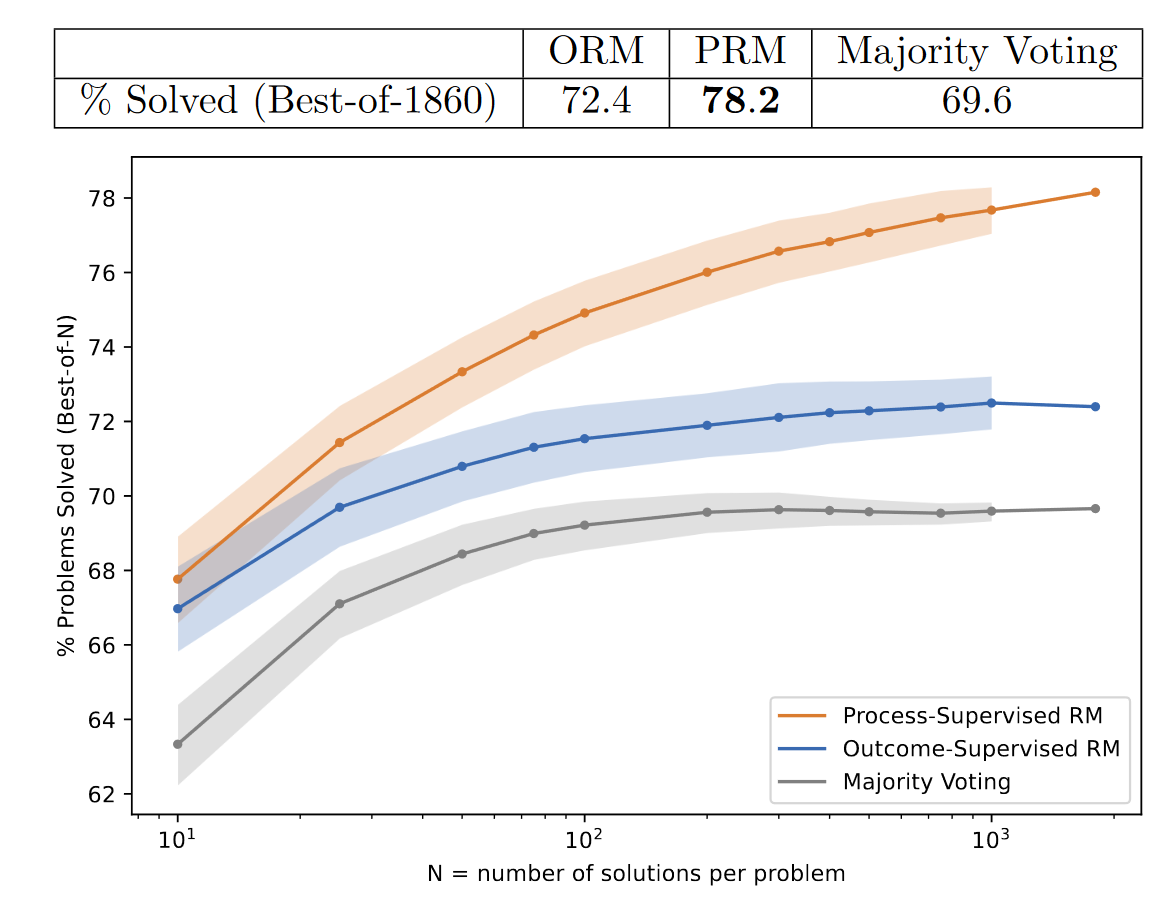
Majority Voting让generator生成N条答案,哪个答案出现的次数最多,哪个答案就对。
奖励模型则会对生成的N条答案进行打分,分数最高的答案就是正确答案。
作者也尝试结合Majority Voting和奖励模型的打分,做一个奖励模型加权的Majority Voting,但是没有明显提升性能。
在较小模型上用生成数据训练奖励模型
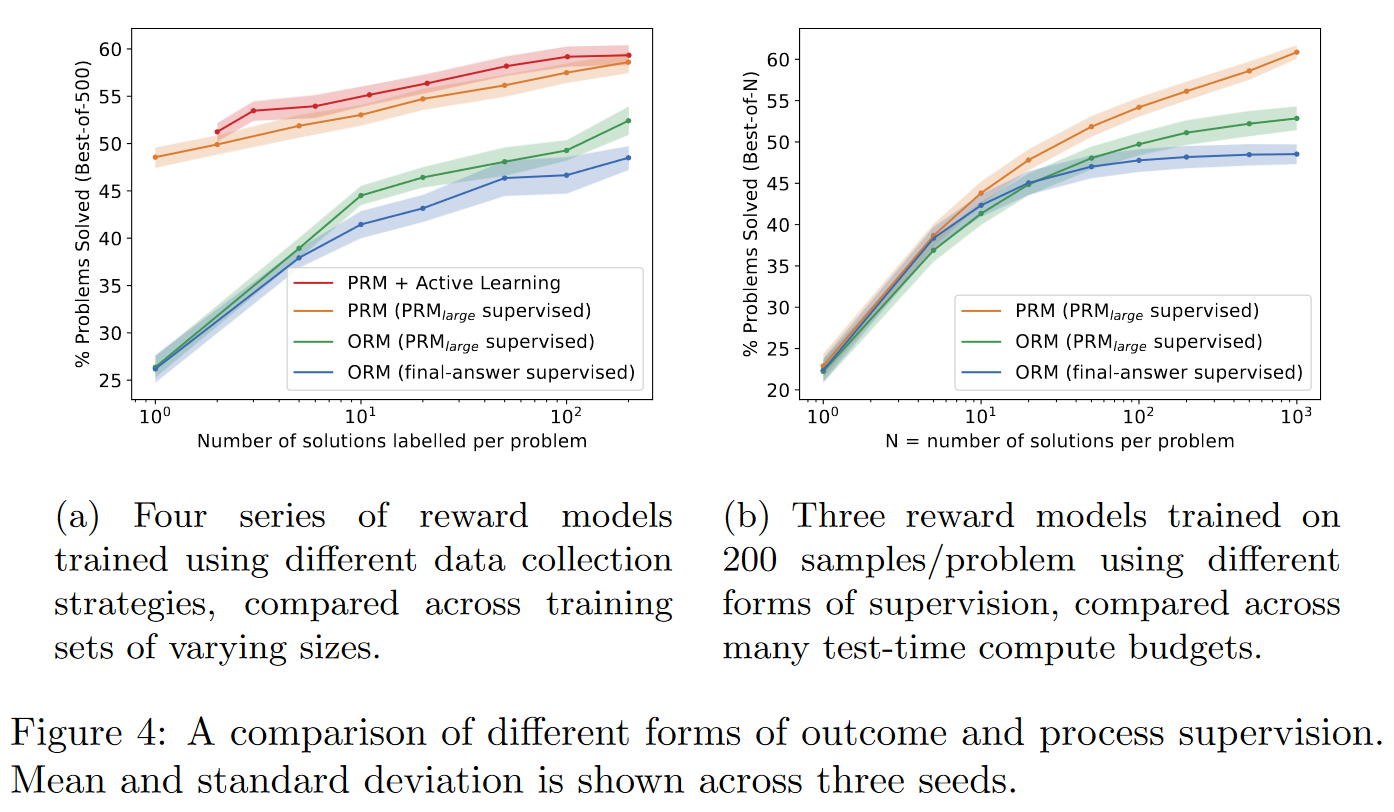
作者用PRM800K训练了一个尽可能好的过程奖励模型
左图展现了:
- 相同标注数据量的情况下,PRM性能更好
- 使用active learning后,能更有效的利用标注数据。
右图主要展现了PRM能从相同数量的解答路径中,更好的选择出正确的答案。
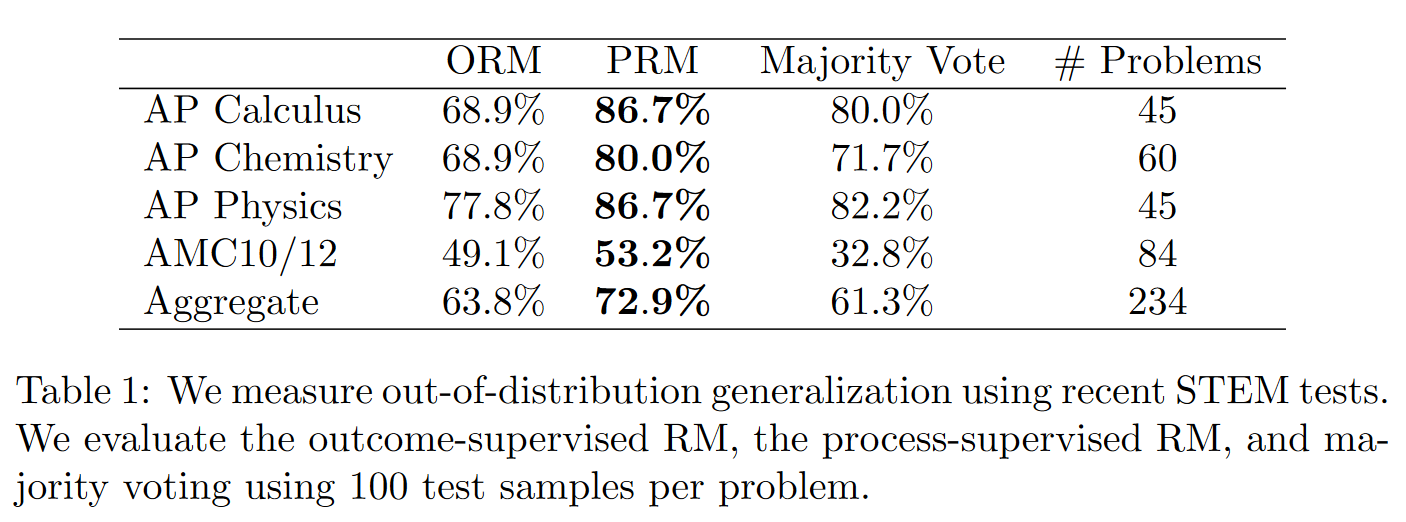
奖励模型的泛化性
下面是使用
结果显示ORM在分布外数据的性能反而比Majority Vote差
PRM还是比Majority Vote和ORM好,意味着它所学到的能力能容忍一定的分布偏移。
讨论
Credit Assignment
结果奖励模型想要泛化的更好,它需要自己搞清楚每一个错误答案哪里错了。如果问题十分复杂,解答过程非常长的话,这个任务就及其困难。过程奖励模型训练时有更丰富的信号,可以知道在出错之前,哪些步骤是正确的,还能知道错误步骤的具体位置。在预测时,也只需要判断每一步是否正确。
作者认为过程监督让Credit assignment变得更容易,因此性能更好。
对Alignment的影响
过程监督鼓励模型产生可解释的推理过程,更安全。
结果监督更难监督,也很难准确传达人类偏好。使用结果作为代理任务,可能让模型学到不受控的行为。Supervise Process, not Outcomes | Ought
个人补充
使用过程奖励模型拒绝采样
如果使用和RLHF一样的方法做强化学习,那么可以使用奖励模型拒绝采样,来得到训练结果的模型的估计值。
过程奖励模型在每个step后进行奖励,因此对生成的每个step,原模型生成这个step的概率为P(step|context)
训练后的模型生成该step的概率应该正比于
可以对原模型的生成结果进行拒绝采样来间接对训练后模型的输出分布进行采样。(拒绝采样见拒绝采样小知识:)
在这里就是要求
使用当前step的错误概率进行拒绝采样
虽然我们还没有确定如果用强化学习优化,奖励应该如何设置。但这里的过程奖励其实有很明显的物理意义,就是(context, step)里的当前step对不对,要不要接受。
而对不对的概率就是奖励模型的输出。所以如果要采样,只需要在生成step后,根据奖励模型输出的正确概率做拒绝采样就好,如果采样结果为正确,就接着生成下一个step,如果采样结果为错误,就重新生成。
反过来,对应的强化学习中应该使用的奖励
其中那个logZ可以是一个训练时固定的系数。让奖励有正有负。
logP则是当正确概率接近于1的时候为0,错误概率大的时候为负无穷,实际操作中可能需要做截断。
为什么这样推导的结果在错误概率大的时候,奖励会是负无穷呢?因为着算法想要大力惩罚错误步骤,宁可让该步骤和原始分布相差较大也在所不惜。
也可以使用其它的奖励设置,比如依据正确/错误概率,让奖励在-1到1之间进行插值。也可以用拒绝采样得到理论上训练后模型的生成结果。