与Open AI o1有关的一些观察和推测
同感,我觉得o1就是用PRM做奖励模型,在PRM上做ppo。但是研究PRM,以及如何更合理的使用PRM做ppo的工作似乎不多。
本文仔细辨析了PRM的含义,并提出一种可能的对step进行ppo的方法。
PRM到底是什么?
在阅读let’s verify step by step论文的时候,遇到一个困惑,就是如何理解PRM给出的正确概率。它的物理意义是什么?
在参考了一些论文后,发现大体上有三种PRM:
- 指到目前为止所有step都正确的概率。
- 指当前step正确的概率。(什么是当前step正确?)
- 指从当前step往后rollout,有多大概率正确。即认为在解答结束的时候给奖励,正确为1,错误为0. 给出当前step的价值函数值。这其实就相当于把解题当成下棋,PRM就是下棋过程中的价值函数。
[2312.08935] Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
从每个step往后rollout,统计有多少答案正确。hard-label是说只要结果有一个答案是正确的,那么当前step就是正确的。这可以被认为是一种启发式的自动标注方案,以最终结果是否正确来判断当前step是否正确,标注一个类似prm800k的数据集。
soft-label是说以往后rollout生成正确结果的频率作为正确概率。这里每个step的正确概率就是上面说的价值函数。
这种outcome supervised的自动标注有一个固有的问题,它依赖于rollout时所使用模型的能力。
作为价值函数的prm
如上所述,这种prm类似于alphago里的价值函数。
首先,这个价值函数一定是和策略函数相关的,往后生成step的模型不同,它所认为的某步step所具有的value也不同。
一千个人眼中有一千个哈姆雷特。举个比较极端的例子,在能自我纠错的o1和初始的gpt3.5眼中,即使是相同的上文,能生成正确结果的概率也完全不同。在一个能完美思考完美纠错的语言模型眼中的价值函数,每一个step的价值都是1. (如果题目有答案) 如果没有答案,每个step的价值都是0,因为总会答错。
接下来就是怎么用这个prm,或者说通过大量采样预训练的价值函数。
如果我们想用ppo来调整策略,由策略梯度的推导,我们可以直接用V(t)对step t的梯度进行加权。V(t)代表从当前step往后的平均收益。因为生成token本身不涉及和环境的交互,因此Q(s,a)=V(s a)
或者减去baseline,使用V(t)-V(t-1)对step t的梯度进行加权,这里的V(t)-V(t-1)就是用价值函数估计出来的优势函数。物理意义是,生成了当前step后,我整个回答正确的概率增大了多少?
进一步,也可以将生成的答案和ground truth对比,获得真正的最终奖励。然后用GAE去加权。
而对应的强化学习的训练目标就是,最大化整个解答的价值,价值就是正确概率,最大为1,最小为0.
但是随着策略训练,这个价值函数(critic model)也需要根据实际生成的输出是否正确而不断调整。当然,如果能继续用大量采样的方式来更新价值函数,或者说认为不同策略对应的价值函数相差不大选择不更新,也是可以的。
但是,一方面如果策略模型推理过程很长,可能用大量采样估计价值函数会很困难。另一方面,策略模型拥有自我纠错能力后,价值函数显然要更新。
像上面所说,这种prm本质是用采样估计出来的价值函数,只能起到更好的奖励分配的作用。强化学习的优化目标还是最终解答的正确性,就是优化更好的outcome reward。
第二,价值函数并不是verify step by step里的prm。价值函数prm在最后一步,会输出整个解答的正确概率,这就是orm。而verify step by step里恰好说明了想要在一次前向传播的过程中完整的验证整个答案(可能很长)的正确性是有困难的,泛化性也有问题。
第三,价值函数通过大量采样对未来的价值做了估计,以此来辅助采样。在alphago里,人们用它来结合信任度上限树(Upper Confidence bound applied to Trees(UCT))来进行策略提升。每次实际下棋时用UCT搜一下。
但是语言模型不同,所谓的思考能力就是搜索答案的能力。我们在概念的迷宫里乱闯,所有的过往都放入context,翻来覆去的思索企图搜索到正确答案。可以说我们真正要训练的是可靠搜索的算法。
我们凭什么相信一个数学证明正确?因为它是“推理步骤”正确的。可靠的推理能力是一种客观的基本的能力,它不是价值函数。价值函数是想要估测之后会发生什么,结局会得到什么奖励,并且将它的预估浓缩成价值,推理能力是向前看,确认当前step和前面的step关系是否正确。它们有关系,但是其实是不同的。
这种采样出来的价值函数即使能在数学领域判断哪一步价值高,我怀疑也不一定能在物理领域判断哪一步价值高,即泛化性差。因为数学和物理毕竟是两种不同的迷宫。而仅仅验证当前step推理是否正确就容易很多。
在verify step by step之前,openai也做过token级别的价值函数prm,并展示了相对orm更好的扩展性。
[2110.14168] Training Verifiers to Solve Math Word Problems
标注出来的prm
标注出来的prm到底是啥?这取决于数据如何标注。
在 Math-Shepherd 里用hard-label标出来的奖励模型,算是用启发式的方法来判断每个step是否正确。假如用于rollout的模型没有任何改错能力,如果当前step能生成一个正确答案,那么确实可以认为它正确。但这种方法似乎噪声太大,太粗糙了。举个例子,假如错误会累积,那么第一个step采样20个才对一个,而往后的step只需要更少的采样就可以判断正误。
AI标注step
我更倾向于基于一些准则,prompt最好的语言模型来对每个step进行标注。并使用prm800k作为测试prompt效果的ground truth. 这种方法在我看来才更容易扩展。似乎没看到有人这样标数据,是因为效果不好吗?还是相对于上面的采样方式来说时间复杂度太高?
相关论文:[2309.00267] RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Specific versus General Principles for Constitutional AI \ Anthropic
使用详细的标注指南比较好还是粗略的指令就足够好了?
prm800k的标注准则
那prm800k的标注准则是啥呢?怎么样的标注准则才能帮助模型更好的思索呢?
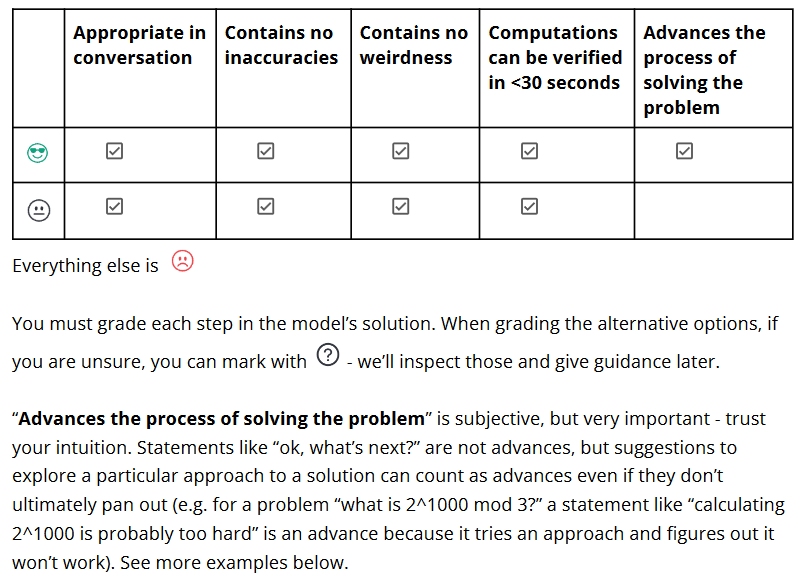
我们仔细看上面这个截图,它要求
好的step:推进对问题的解答,不要包含太多内容尽可能容易验证(<30s),尽可能准确
中性step:没推进问题的解答但也不算错
坏的step:错
对是否正确还有更详细的描述和说明,见 PRM800K标注指南
从上面的描述我们发现了两点:
- 鼓励容易验证的step,这意味着1. 方便我上面所说的用prompt自动化标注 2. 强化学习过程中,对策略模型最经济的方式就是拆分步骤生成容易验证的step
- 好的step是能推进问题解答的,这种对解题来说相当重要的属性是来自于人类标注员的直觉。在上面的价值函数prm中,我们尝试用大量搜索根据最终答案来统计出这种直觉,是否推进了问题解答体现为优势函数V(t)-V(t-1)是否大于0,但效果似乎不佳。
如何理解训练出来的PRM
标注时让人逐步验证step的正确性,标注在出现正确结果或出现第一个错误step停止。具体参见标注的数据文件。训练详情见论文。
如何理解训练出来的奖励模型呢?我们看论文中给出的例子,红色表示错误,绿色是正确。
与价值函数prm不同,它不是到目前为止所有step正确的概率,是当前step正确的概率。从例子中可以看到,即使前面有step错了,后面的step也可以是被标注为正确的。
那么什么是当前step正确的概率?如果前面有任何错误,那么一个足够严苛的奖励模型眼里唯一正确的事情或许就是改正错误。
我对它的理解方式是,PRM每次给当前step评分时,先查询上文中所有相关step,并检查这些step的内容是否有矛盾,如果有矛盾,当前step最正确的做法就是修正矛盾(比如提出解释,修复错误),如果相关step没有发现矛盾,就检查这些相关step是否能推出当前step。
它的好处就是,不需要检查可能超级长的所有上文step是否正确。更加“局部”的判断当前step的正确性。



最后,也是最关键的问题,就是怎么用真实标注训练出来的prm进行强化学习训练。
我给出一个最符合我自己直觉的说法,然后尝试说服大家。
step level ppo
思路是对每个step做ppo,而不是对整个解答过程做ppo。也就是说,每个step里的token只能看到当前step的奖励,看不到之后step的奖励。
而在每个step内部,强化学习(奖励分配)的方法和单轮对话的rlhf一样。所有单轮对话用的强化学习技巧都可以用到这里。
下面开始尝试说服:
我们假设每一步推理好不好,仅仅由当前step的奖励决定,和之后生成的步骤无关。后面step的奖励无论对错,都和之前step没有关系。无论是否最后生成了正确答案,只要我过程正确了,每一步的行为就能马上获得奖励。
- 这样的好处首先是只需要在step的长度上估计优势函数了,优势函数的方差变小了。
- 忽略之后step的奖励,意味着:对于正确的step,我们不需要为未来的失误买单。对于错误的step,即使未来改正了,结果也对了,错误的step还是应该被惩罚。
- 仅使用当前step的奖励,忽略之后step的奖励,意味着模型不是在最大化整个回答的序列奖励。
- 如果是最大化回答的序列奖励,我们可能会鼓励模型在当前step采取一些能避免在之后的step犯错的动作。如果只是最大化step的奖励,则不会鼓励这点。在推理时,做一些防止自己之后犯错的动作好像没什么太大意义。(举个例子,我们不应该鼓励在算题时发现某题原则上可以解出来,但因为计算复杂非常容易出错,而不去算。是否能解出来和自己是否容易出错是两个问题。)(再举个例子,直接最大化序列奖励会导致鼓励模型不断重复对但是无用的中性回答,因为这样未来的奖励才最大)
- 屏蔽后面step的奖励可能会:导致问题无法推进,解决问题时没有方向,激励模型不断说正确但是不能解决问题的话。但这一点其实在上文中数据标注的部分考虑过了,在标注数据时,要求标注人员按直觉把能推进问题解决的step标为positive。这意味着解决问题的前景,尝试,都已经包含在当前step的reward里了。(所以说方法很直接,关键在于数据标注!)
对一个理想的大语言模型来说,每个step犯错的概率是恒定的。那么这个时候未来的奖励就与当前step无关,最大化序列奖励等于最大化step奖励。简化梯度权重中未来的奖励
其它使用prm做ppo的论文:
使用PRM以最大化序列奖励为目标做强化学习时的reward hacking一例:
[2410.15115] On Designing Effective RL Reward at Training Time for LLM Reasoning
STEP-RLHF: Step-wise Reinforcement Learning from Human Feedback
这篇文章很怪,早早的发了,匿名挂在openreview上。也不知道是谁的文章,也没有代码。也是step level ppo,似乎没人跟着做。缺点如下
- 没说为啥step级别的ppo好,不同在哪
- 查看公式,发现估计价值函数的目标(return)的公式似乎写错了。我不太理解
- 算训练奖励模型时不是直接用的prm800k,自己又基于prm800k构建了一个step级的偏好数据集,然后再训练。可能是为了获得连续的奖励值吧…不太清楚怎么构造的,但真的有必要吗?
- 怀疑是否真的做了实验,实验是否真的说明问题。把idea做work也不容易,就像在verify step by step之前也有工作说prm和orm效果一样
结语
本文辨析了PRM的类别,并提出使用step level ppo来对PRM做强化学习。并猜想这是实现o1的关键方法。
强化学习的部分可以说是相当简单,并没有什么特别的。关键在于数据标注。
另外如果只是着眼于让模型做对题目,以答案作为奖励的最终来源,那么中间步骤似乎很难定义有意义的reward。而如果认为思考属于一种搜索,那么使用中间步骤的reward来教会语言模型可靠的思索就很有必要。从日常经验中看,思考是一种搜索,像是走迷宫,先凭感觉走,走到一个死胡同然后就回头,不断试错最终找到答案。对于“死胡同”和“试错”这种行为,用价值函数来描述可能很不方便。
另外,在实现o1时,还需要某种控制推理生成长度的方法。(在prompt有长度约束的情况下以长度为奖励等等方法增强指令遵循能力)
或者还需要在奖励模型最后添加对最终结果是否正确的奖励。
因为奖励的类型不同,也许还需要训练多个不同的critic model做奖励分配估计优势函数,然后相加成为逐token梯度的权重。
这个代码实现上其实很简单,和普通ppo差不多,只是在计算GAE的时候要改一下。自己刚好也有在看openrlhf的源码。于是自己尝试去改openrlhf的源码实现,但是意外的发现在tokenize之类比较细节的地方卡住了。而且自己也没有卡,不太好验证正确性。还是等有资源的大佬试一试吧
其它
关于模型的自我纠错能力:
- 如何教模型知错能改?还是说不用教,模型会自己涌现出这种能力?
- (ICML 2024 Tutorial: Physics of Language Models - YouTube Part 2.2 提到语言模型是可能自己学会改错的,这种能力很可能来自于预训练中包含的自我纠错数据)
- 【中英字幕】 10月2日,OpenAI的Noam Brown及其团队谈论了o1以及如何教大语言模型更好地推理|红杉|深度强化学习|2024.10.02_哔哩哔哩_bilibili 18:15时提到这种backtracking能力是通过训练模型做更长的推理时自动出现的,而非手动构建。Noam提到他们讨论了很久如何构建这种backtracking的能力,最后觉得还是先训练模型能思考更长时间做为baseline再说,结果这种能力就自动出现了。这种训练方法是干净和可扩展的。
其它有趣的特点:
强化学习训练出来的每个模型在各方面的能力上都各有不同
OpenAI o1 团队采访的完整版【2024.09.20】_哔哩哔哩_bilibili 21:34
通过prompt模拟o1:
Can we make any smaller opensource LLM models smarter than human? | by Harish SG | Oct, 2024 | Medium
这里使用结构化的prompt指令,利用claude强大的指令遵循能力来实现了类似o1的效果。这当然也可以,但我觉得关键在于那个监督step的过程奖励模型以及对强化学习训练方法的探索。过程奖励模型也可以用来确保一些别的东西“合规”,如果更短时间片上的强化学习行得通则可以在此基础上进一步探索如何在和环境交互的过程中做强化学习(奖励分配),多个奖励如何设置,等等。o1生成的数据也可以放到预训练阶段,或者说蒸馏一个小的专精推理的模型。所以训练o1肯定是有意义的,不仅仅是把prompt的效果压缩到模型里。