KV Cache推理优化
根据公式总结有四类方式
2 x Length x batch_size x [d x n_kv_heads] x Layers x k-bits x 内存模型
n_kv_heads:MQA/GQA通过减少KV的头数减少显存占用Length: 通过减少长度L, 以减少KV显存占用,如使用循环队列管理窗口KVKV-Cache的管理:从操作系统的内存管理角度,减少碎片,如Paged AttentionK-bits: 从量化角度减少KV cache的宽度,如使用LLM-QAT进行量化
1. 减少头数 MQA/GQA
GQA: 2305.13245.pdf
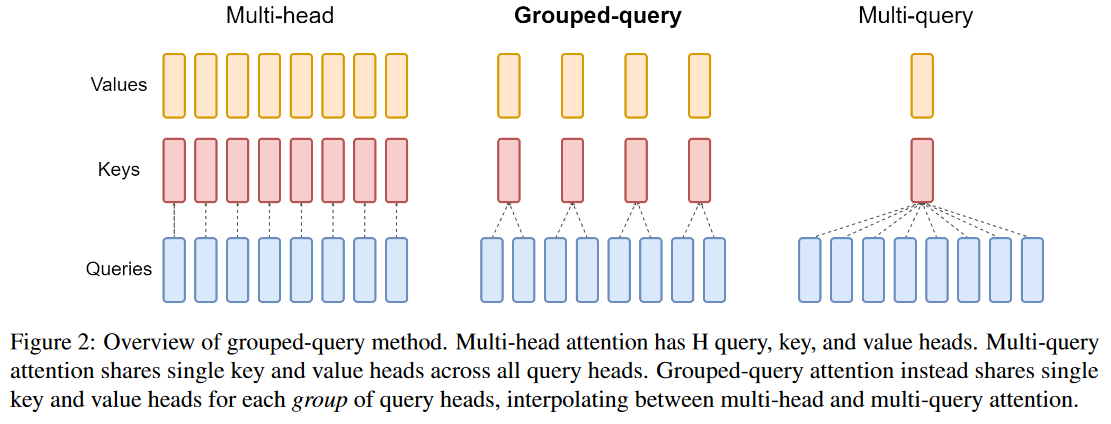
多头自注意力有多个头,每个query head都对应一个key value head
Multi-query attention有多个query head,但是每个query head都只对应相同的key value。也就是说n_kv_heads=1
Grouped-query attention 有多个query head,每组query head对应相同的key value。也就是说n_kv_heads=n_q_heads/q_groups
自己觉得下图其实有一定误导性,但是配上下面的文字说明应该是比较清楚。
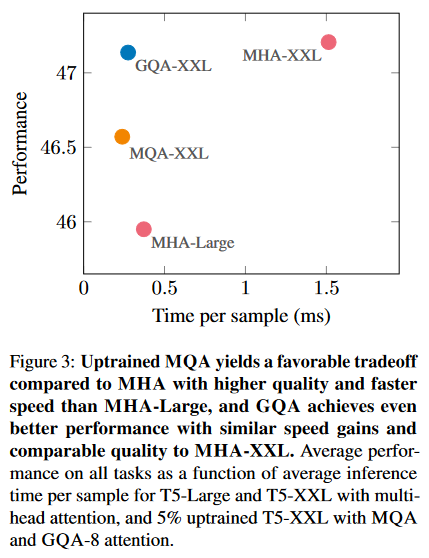
推理耗时/性能对比图,GQA推理时间变成三分之一,性能差不多。因此llama模型在训练时采用的就是GQA。通过减少KV的头数,可以减少kv-cache的显存占用,加快训练和推理。
缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA - 科学空间|Scientific Spaces