LLM量化
这里主要总结一下自己了解过的LLM常用量化方法
训练后量化
旋转量化
通过旋转矩阵减少离群值
[2405.16406] SpinQuant: LLM quantization with learned rotations
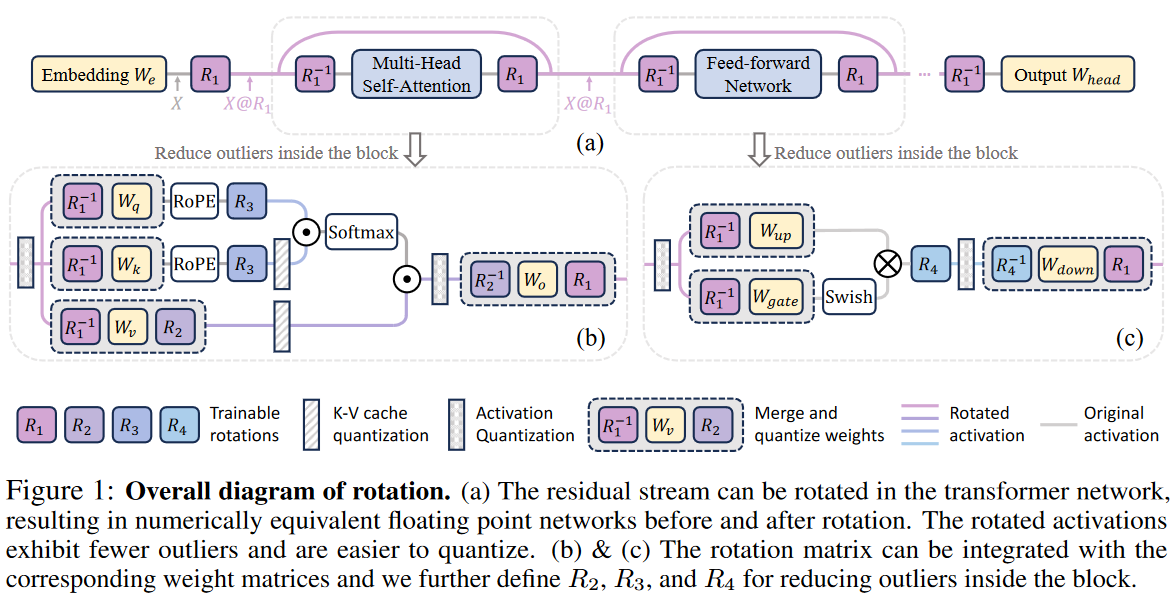
不同旋转矩阵,对减少离群值的效果不同,本文使用Cayley SGD优化这些单位正交矩阵。优化目标不是调整全精度网络的输出,而是让中间激活和权重更方便量化
zhuanlan.zhihu.com/p/701646738
kv-cache量化
QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead | Cool Papers - Immersive Paper Discovery
让人惊叹的Johnson-Lindenstrauss引理:理论篇 - 科学空间|Scientific Spaces
(用随机高斯矩阵来投影然后量化,类似于旋转矩阵?)
让人惊叹的Johnson-Lindenstrauss引理:应用篇 - 科学空间|Scientific Spaces里局部敏感哈希那一节和本文方法差不多
高维随机向量近似正交,下面这样可以造出近似的单位正交矩阵(旋转矩阵)
import numpy as np
def generate_bernoulli_matrix(N):
# 生成N*N的随机矩阵,元素来自{-1, 1}的均匀分布
matrix = 2 * np.random.randint(2, size=(N, N)) - 1 # 生成{-1, 1}的矩阵
# 缩放矩阵元素以满足方差为1/N
matrix = matrix.astype(float)* np.sqrt(1 / N)
return matrix
def generate_gaussian_matrix(N):
# 生成N*N的随机矩阵,元素来自均值为0、方差为1/N的正态分布
matrix = np.random.randn(N, N) / np.sqrt(N)
return matrix
def check_orthogonality(matrix):
# 矩阵转置并相乘
result = matrix.T @ matrix
# 检查是否近似为单位矩阵
error = np.square(result - np.eye(result.shape[0])).mean()
return error
# 设定矩阵大小N
N = 100
# 生成随机矩阵并检查正交性
matrix_bernoulli = generate_bernoulli_matrix(N)
print(check_orthogonality(matrix_bernoulli))
print(check_orthogonality(generate_gaussian_matrix(N)))将高维向量
原因:
本文利用
先看
至于
这样就把

这个方法实际上是在对点积做近似,与q,k分布无关。因为点积结果差不多,所以注意力也可以近似的算出来。文中还说明了为了减少注意力概率分布的误差,m相对于logn越大越好,k向量模长越小越好。(这里的n是指序列长度)(好糟糕的概括orz)
对k-cache中离群值的处理
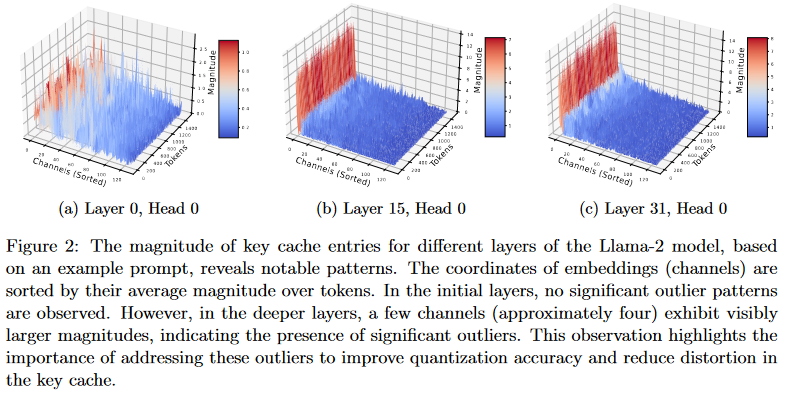
离群值对k向量模长贡献最大,因此可以将它排除在QJL算法之外。另外的对离群值维度算点积,然后和QJL维度算出来的近似点积结果相加。
让随机矩阵的行正交有利于性能
实践上,作者生成随机矩阵S,然后对行做QR分解,让它行与行之间正交
量化感知训练
[2004.09602] Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation
[2106.08295] A White Paper on Neural Network Quantization
[2103.13630] A Survey of Quantization Methods for Efficient Neural Network Inference
[2303.17951] FP8 versus INT8 for efficient deep learning inference