GPipe
[1811.06965] GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
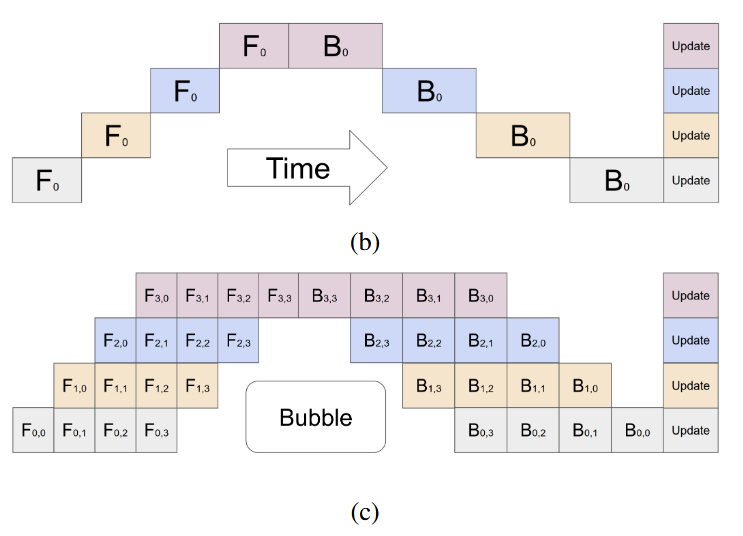
图中横轴为时间,纵轴为设备,设备数都是p=4
不同的设备上保存模型的不同层,在前向计算时,上面的设备依赖下层的设备,反向传播时则反过来。
图b中,micro batch size = batch size。因为设备之间的计算存在相互依赖的关系,同一批数据,不同层之间的前向计算和反向计算相互依赖,这导致了空泡很多。
图c是GPipe提出的办法,就是将一个batch分成多个micro batch,同一设备上在不同时间可以执行不同的micro batch,这些micro batch之间的计算没有依赖。图中是分成四个micro batch(横轴)
最后在执行完这个batch的数据后,统一更新参数。
理论空泡率估计
设备数K,每个batch分成M个micro batch
看图发现,每个设备空泡数正比于设备数,即K-1,非空闲时间块正比于M,所以空泡比例为
这样看来,只要增加M,就能减少空泡率。原论文中实验表明,当M>=K时,空泡开销就可以忽略。但是因为存在通信开销,不能无脑增加M。(通信开销是时延为主还是带宽为主?)
重计算
Gradient Checkpointing
GPipe还可以利用重计算来减小中间激活的存储,从而增大batch size,增大整体吞吐
为了能够反向传播计算梯度,我们需要前向传播的中间结果。如果不使用重计算,每一层都要存储自己的激活值。
假如模型一共L层,每层宽度为d,batch size为N,micro batch size为N/M。对每块设备,中间激活占用的峰值内存为
对GPipe来说,每个设备包含模型连续的L/K层。如果每次前向计算后,只保留这连续的L/K层的输入激活值。那么反向计算的时候,就需要重新计算中间激活值,然后反向传播。
这种情况下总的峰值内存占用为
重计算可以降低相同batch size下的显存的占用,但是计算代价如何呢?
重新计算中间激活值需要的时间和前向传播是一样的。对一个micro batch,在某个设备上前向传播时间 : 重计算时间 : 反向传播时间 = 1:1:2
也就是说,没使用重计算时,图c中B的宽度是F的两倍,使用重计算后,B前面要增加一块时间F’。而由于重计算F’不依赖于前面的设备,所以在反向传播中可以被掩盖掉。
所以,前向计算时间
近似为
反而降低了空泡率,虽然是以重复的计算为代价,但是反过来能增大batch size和吞吐呢~
其它
最后,因为对batch进行了切分,在计算batch norm时会有影响,但是layer norm是在每份数据内计算的,所以没有影响。
哎,人家写的比我写的好多了 图解大模型训练之:流水线并行(Pipeline Parallelism),以Gpipe为例 - 知乎
里面把使用更多gpu的原因分成两类,一类是为了训练更大的模型,另一类是为了更快的训练速度。
第一个是GPU数量 VS 模型大小,是希望模型大小能随着gpu数量正比增加。这和模型是否能均匀划分到gpu上有关。如果不能均匀划分的话,除了某块gpu的内存会成为短板,运算时间也会成为短板。
第二个是GPU数量 VS 训练速度。这里的训练速度指的是训练吞吐。想看训练吞吐能否随着设备数线性增加。在作者的实验中看到,当通信开销大的时候,相同模型的训练吞吐没法线性增加。当通信开销小的时候,可以放心的增大M,减少空泡,从而让训练吞吐随gpu数量线性增加。我觉得这种训练吞吐增加应该来自于batch size的增加。
其实还是有点没有太想明白,各种因素都会对性能产生影响,还要和其它并行方法对比,哎哎(
大模型训练 Pipeline Parallel 流水并行性能分析 - 知乎
下面的算法了解过,但是忘了,所以还是不知道。复制一段别人的文章过来充数,下次补上(
1F1B
1F1B (在流水线并行中,pipeline stage 前向计算和反向计算交叉进行的方式)流水线并行方式解决了这个问题。在 1F1B 模式下,前向计算和反向计算交叉进行,可以及时释放不必要的中间变量。
PipeDream
PipeDream 在单个 GPU 上进行短暂的运行时性能分析后,可以自动决定怎样分割这些 DNN 算子,如何平衡不同 stage 之间的计算负载,而同时尽可能减少目标平台上的通信量。PipeDream将DNN的这些层划分为多个阶段——每个阶段(stage)由模型中的一组连续层组成。PipeDream把模型的不同的阶段部署在不同的机器上,每个阶段可能有不同的replication。该阶段对本阶段中所有层执行向前和向后传递。PipeDream将包含输入层的阶段称为输入阶段,将包含输出层的阶段称为输出阶段。
Virtual Pipe
virtual pipeline 是 Megatron-2 这篇论文中最主要的一个创新点。传统的 pipeline 并行通常会在一个 Device 上放置几个 block,我理解这是为了扩展效率考虑,在计算强度和通信强度中间取一个平衡。但 virtual pipeline 的却反其道而行之,在 device 数量不变的情况下,分出更多的 pipeline stage,以更多的通信量,换取空泡比率降低,减小了 step e2e 用时。