[1710.03740] Mixed Precision Training
混合精度训练过程
混合精度训练想使用fp16来对模型算梯度,然后用算出来的fp16的梯度去更新模型fp32版本的参数。
训练过程如下图,先是用master-weight复制一份fp16的模型权重。然后对该层前向计算激活值,反向计算输入激活值的梯度,计算权重的梯度(都是fp16)。然后用权重的梯度(fp16)来更新fp32的模型权重。
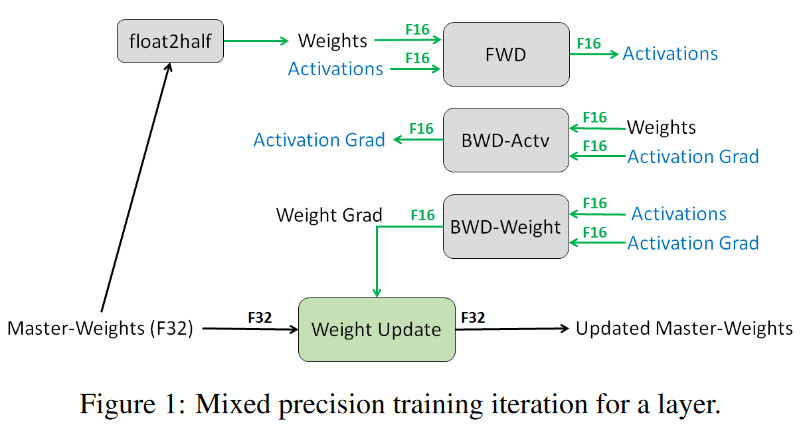
分析
显存
我看到这方法的第一个印象就是可以节省显存,但是果真如此吗?下面是一些分析
令模型权重大小(fp16)=w,模型权重大小(fp32)=2w,模型梯度(fp32)=2w,优化器状态(fp32)=4w(假定是adam)
激活值大小(fp16)=ac,激活值大小(fp32)=2ac
没用混合精度训练时总的参数量
模型权重(fp32)+优化器状态(fp32)+激活值(fp32)+梯度(fp32)
= 8w+2ac
用混合精度训练时的总参数量
模型权重(fp32)+优化器状态(fp32)+模型权重(fp16)+激活值(fp16)+梯度(fp16)
= 2w+4w+w+ac+w=8w+ac
这样看来,混合精度训练可以增大一倍batch size
就算不增大batch size,因为主要的计算都变成fp16了,也是可以加快训练的。
精度问题
但是训练出来的模型性能如何,会不会因为数值精度出现无法训练的情况呢?为此去仔细看了一下论文的实验和分析。
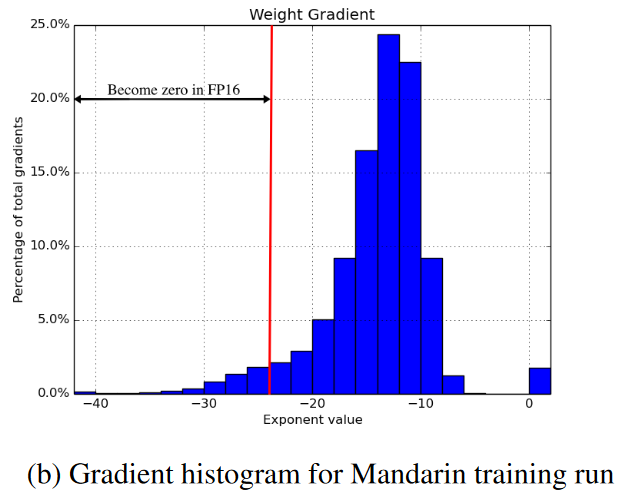
1. gradient的取值范围
上面的训练过程里说了,反向传播算出来的weight gradient是fp16的,但是fp16的指数位比fp32更小。浮点数是通过类似于科学计数法的机制来表示大小的。因此指数位小,就意味着表示范围更小 按照IEEE的表示标准,min(fp16)>min(fp32)(假设都是正浮点数)
下图中展示了一次训练中weight gradient的取值范围,小于fp16的最小值的数会出现下溢。
下图展示的是activation gradient的取值范围,相比于weight gradient有更大的比例会underflow
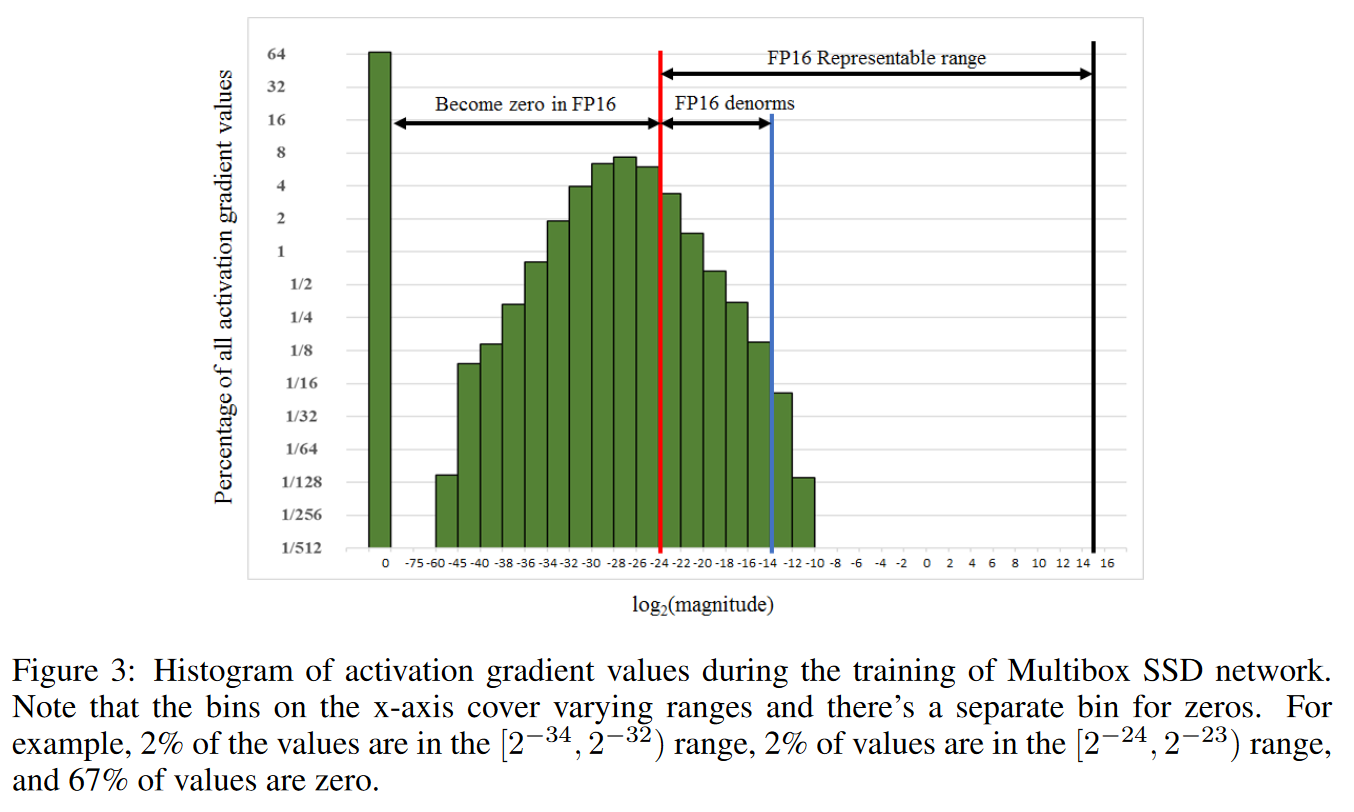
计算梯度所需的取值范围,可能会小于fp16的取值范围。而由于链式法则,我们可以简单的在输入端乘一个缩放系数来让反向传播的梯度整体增大/减小。从而让反向传播的梯度在fp16可表示的范围内。最后在更新时,缩放回去就可以了。但如果缩放后的结果还是用fp16表示,还是会下溢,因此需要转换成fp32,然后放到优化器里再去更新参数。
输入数据不同,模型不同,最合适的缩放系数也不同。因此可以自适应的调整,一个方法是按照规则不断尝试增大缩放系数,出现overflow就停止尝试。(当然如果梯度数值的取值范围实在太大就训练不了啦)
另外除了fp16,bf16有与fp32相同的指数位和更小的小数位。看起来也许是不需要缩放了?
#todo
上面只是说了gradient的取值范围,没有提weight从fp32转换成fp16时超过取值范围会如何。也许只是简单的截断?
2. 更新时的舍入误差
刚刚说的是反向传播时可能存在的精度问题。下面是模型进行参数更新时可能出现的精度问题。
参数更新涉及到一个大数(权重)加一个小数(更新量),因此可能会出现舍入误差(rounding error)
如果用fp16来表示权重和更新量,即使更新量可以用fp16表示,权重在更新时依然可能不动。因为fp16的小数位太少了,如果权重是更新量的很多很多倍,更新量在fp16的权重上就无法表示出来。或者简单来说就是fp16的小数位太少了,一些小的梯度更新信息达不到fp16的最低分辨率。
3. 计算精度
前向计算时,单纯用fp16也可能会不够用。论文对前向计算分成了三类:向量点积,reduction计算,逐点计算
前两者在计算时最好使用fp32来累积计算中间结果,然后在写回显存时使用fp16的精度。
结语
为了减少显存消耗、加快计算,混合精度训练使用了fp16来前向计算和反向传播来估计梯度。作为结果的fp16梯度,会存在一定程度的不准确,但是只要不大量溢出,就没什么问题。毕竟“随机”梯度下降,梯度本身就是随机估计的嘛。反过来说,通过降低显存开销,增大batch size,估计出来的梯度说不定更准确呢?
哎,那最终训练出来的模型是fp32的还是fp16的?
我觉得是fp16的,因为前向计算,和算损失时都是在fp16的版本上算的。整个训练过程中并没有直接在fp32版本上前向计算过。
pytorch里的自动混合精度训练
PyTorch的自动混合精度(AMP) - 知乎
参考上面博客的代码,有两部分
一个是torch.cuda.amp模块中的autocast类,用上下文管理器把模型自动转换成fp16
另一个是GradScaler对象,用于缩放loss,把梯度从fp16转成fp32,检查梯度是否上溢/下溢,如果没有就调用优化器更新梯度,如果有溢出就不更新,调整缩放系数。