GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection | Papers With Code
效果

与LoRA比较
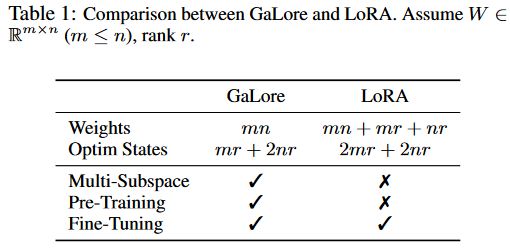
W(mxn)
LoRA: W=AB A(mxr) B(rxn)
GaLore: 投影矩阵P(mxr) 优化器记录的状态
G是W的梯度
更省优化器状态的内存
相关工作
- Low-Rank Adaptation
- 精调阶段的LoRA,在W的基础上训练
。 是由AB两个矩阵相乘得出的低秩矩阵。需要训练的参数量从W降低到A+B - ReLoRA,将lora的想法运用到预训练阶段。不断将
合并到参数矩阵W上,从而在可训练参数比较低的情况下增加W的秩。需要在开始时用全参数预训练来warm up以达到比较好的效果。
- 精调阶段的LoRA,在W的基础上训练
- Subspace Learning
- 有些工作发现学习主要发生在所有参数空间的一个低维子空间里。本文也是在让某几个训练步骤在一个低维子空间学习。
- Projected Gradient Descent
- 内存高效优化
- Adafactor对优化器的二阶统计量进行近似,利用了二阶统计量的低秩性。
方法
本文的idea是利用W的梯度缓慢改变的低秩结构,来压缩梯度,压缩优化器参数,从而省内存。而不是像LoRA直接对W用低秩近似。
动机:每一个batch计算出来的梯度大概率是低秩的
文中做了些证明。其实也可以这样理解,用lora精调语言模型就相当于对参数做更新,这个更新量的主要部分是低秩的,而更新量是梯度在某个方向上的累积。因此梯度也大概率是低秩的。
利用这一点,作者通过乘一个压缩矩阵P,压缩了每一步计算出来的梯度grad_W。进一步用压缩后的梯度更新优化器状态,然后将优化器算出来的更新量解压回原始参数矩阵W的大小,用于更新参数矩阵W。


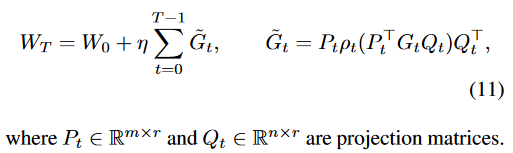
投影矩阵P是通过对梯度做SVD分解算出来的。选取前几列,转置左乘到梯度G上,从而对行进行压缩。同样也可以选择右乘一个矩阵Q来投影。
文中证明了如果固定投影矩阵,训练是可以收敛的。
下面说明了每过几步更新投影矩阵的必要性。假如固定投影矩阵,相当于限制了所有梯度更新的方向,梯度更新只能在那个子平面上进行。通过定时更新投影矩阵,可以扩展可能的优化空间。
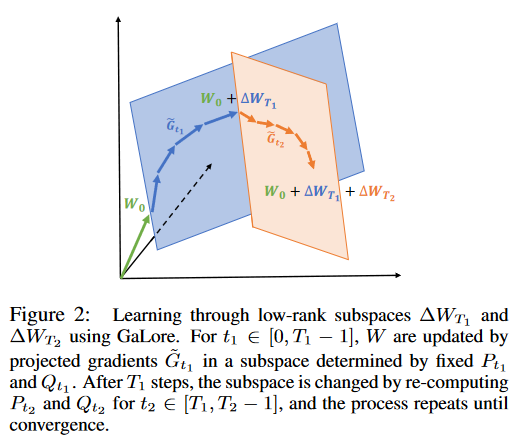
看了上面的伪代码,应该都清楚这算法是怎么回事了。但是这样做合理吗?
AdamW状态参数并不对应任何实际的参数。每次修改投影矩阵,它记录的一阶和二阶统计量都完全不是同一个东西了,这样也没问题吗?所以投影矩阵更新过快可能造成训练不稳定
作者在130M的语言模型上实验后发现500~1000是差不多最优的。
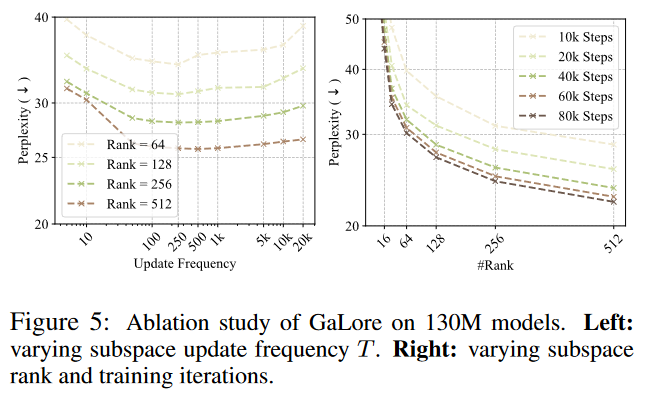
另一个问题是投影矩阵的选取。它来自于当前batch估计的梯度的SVD分解算出的特征向量。但是这本身有一定随机性。文中好像也没说明几个batch算出来的梯度的特征向量确实是缓慢改变的。只是说利用W的梯度缓慢改变的低秩结构,但没说是不是缓慢改变的。对这个梯度压缩比较好,对下一个梯度也是吗?不知道啊,不过有用就行。作者说“As Theorem 3.6 does not require the projection matrix to be carefully calibrated, we can further reduce the memory cost of projection matrices by quantization and efficient parameterization”,难道随便找个都行?
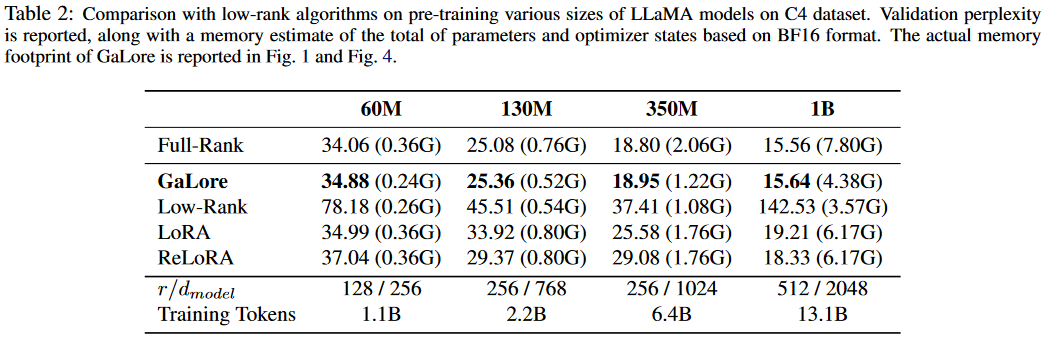
看看实验,r是模型维度的1/4,优化器占用内存变成1/4. perplexity略差一点。
还有一些实验和关于低比特adam优化器状态的就先不看了