下面介绍一些分布式通信原语
一对多
- Broadcast(广播,总共有p张卡,把一张卡上的数据发送到其他p-1卡上)
- Scatter(打散,把一张卡上的数据分成p份,将p-1份数据分别发送到其他p-1张卡上)
多对一
- Reduce(将所有p张卡上的数据相加(或者相乘等满足交换律和结合律的操作))
- Gather(收集,反向scatter)
多对多
- All Reduce
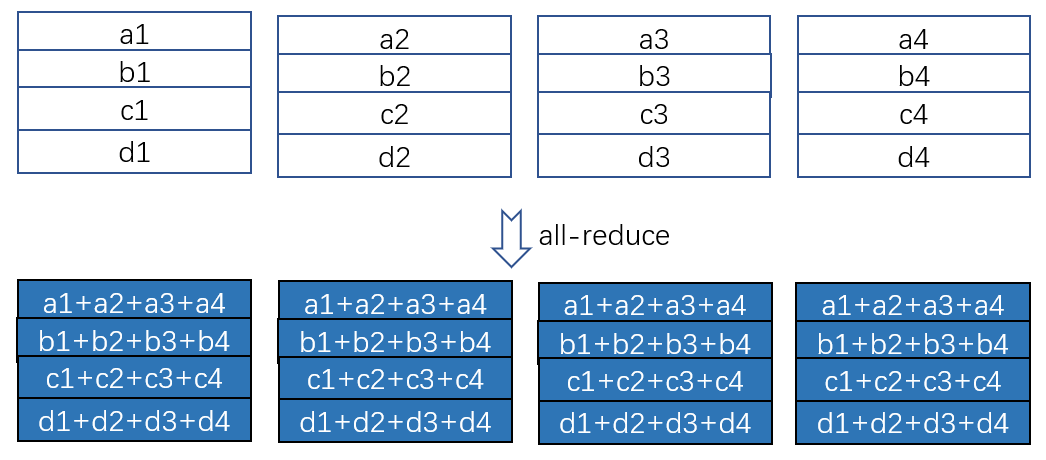
- Reduce + Broadcast
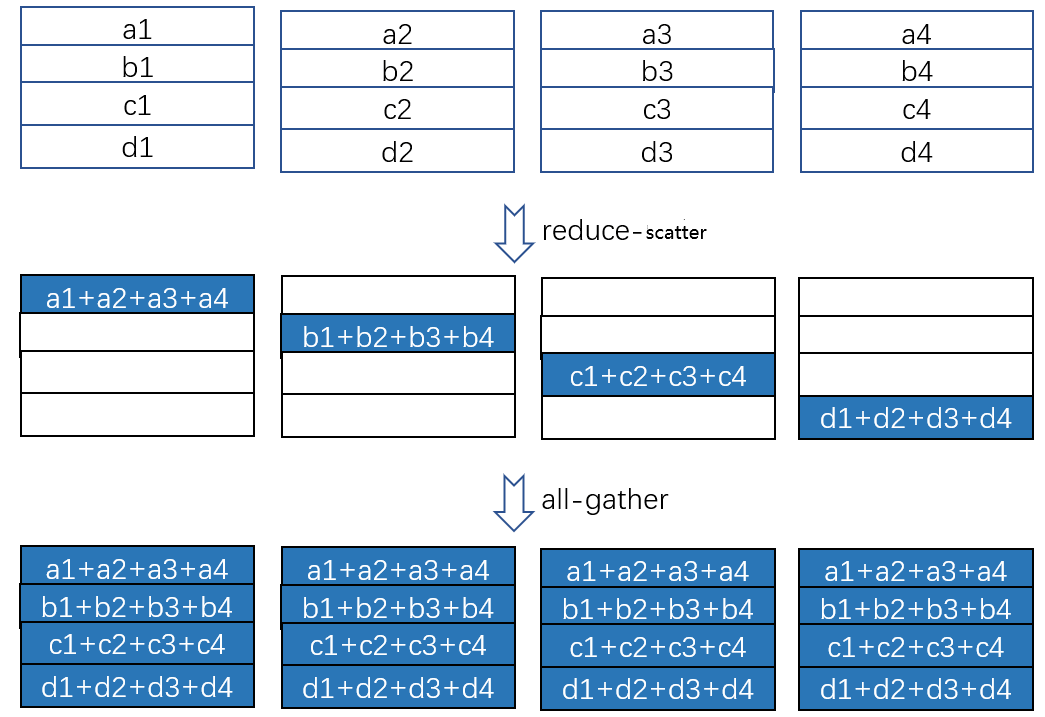
- Reduce-Scatter + All-gather
- All Gather=Gather + Broadcast
- Reduce Scatter(数据x卡的矩阵上来看是对行求和+乘对角矩阵)
- 是All Reduce但是将每个机器只有一部分Reduce后的数据,而不是所有机器有全部数据。因此从这个意义上来说是Scatter
- Ring all reduce=Ring Reduce scatter + Ring all gather(这里的reduce scatter和all gather都是通过环的方式做
- All to All(从数据x卡的矩阵上来看就是转置)
ring all-reduce的通信量
实现时分为两步,ring all reduce = ring Reduce-Scatter + ring All-gather
假设单张卡上总数据量为V,有p张卡。卡之间连成一个环,并且只能顺时针单向通信。
第一步ring reduce-scatter将每个设备上的数据V分成p份,每份数据大小为V/p,分别reduce到各个设备上。
过程如下图,图中p=4
每一次通信,每个设备都向相邻的设备发送V/p的数据,令带宽为
一共需要p-1次通信,总通信时间为
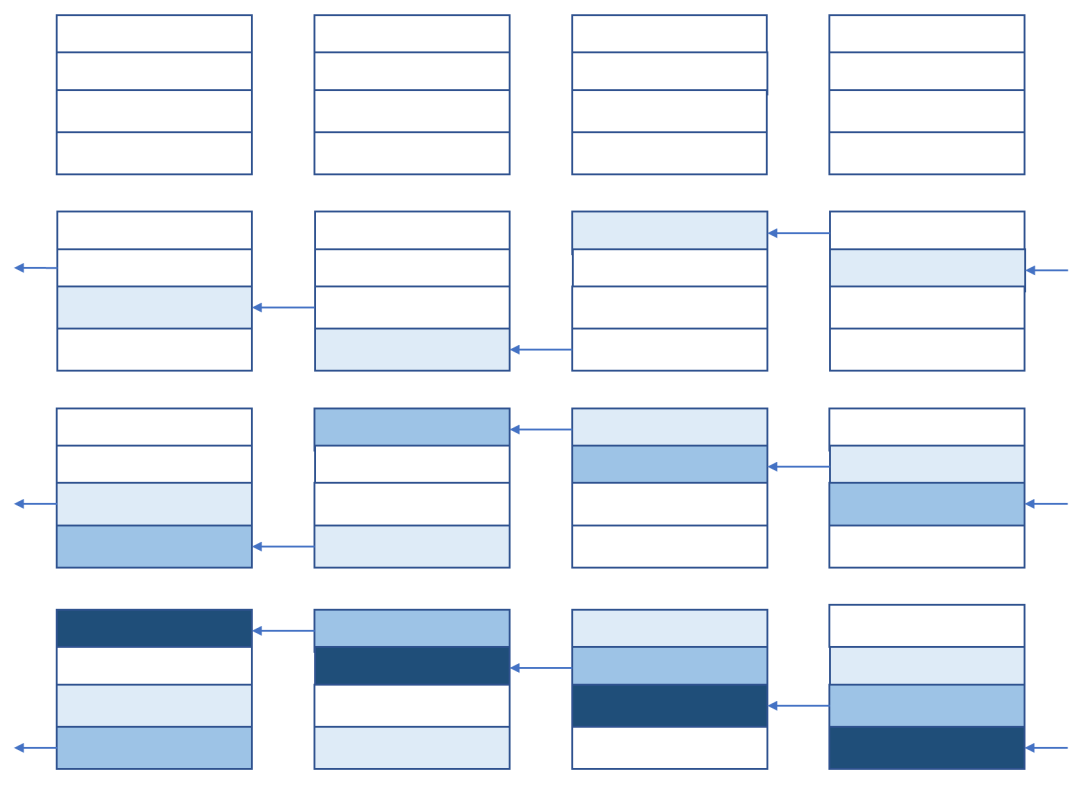
做完ring reduce-scatter后,每张卡上都有一部分reduce后的正确结果。需要分别将大小为V/p的正确结果发送到其他设备上。
第二步ring all-gather的过程如下
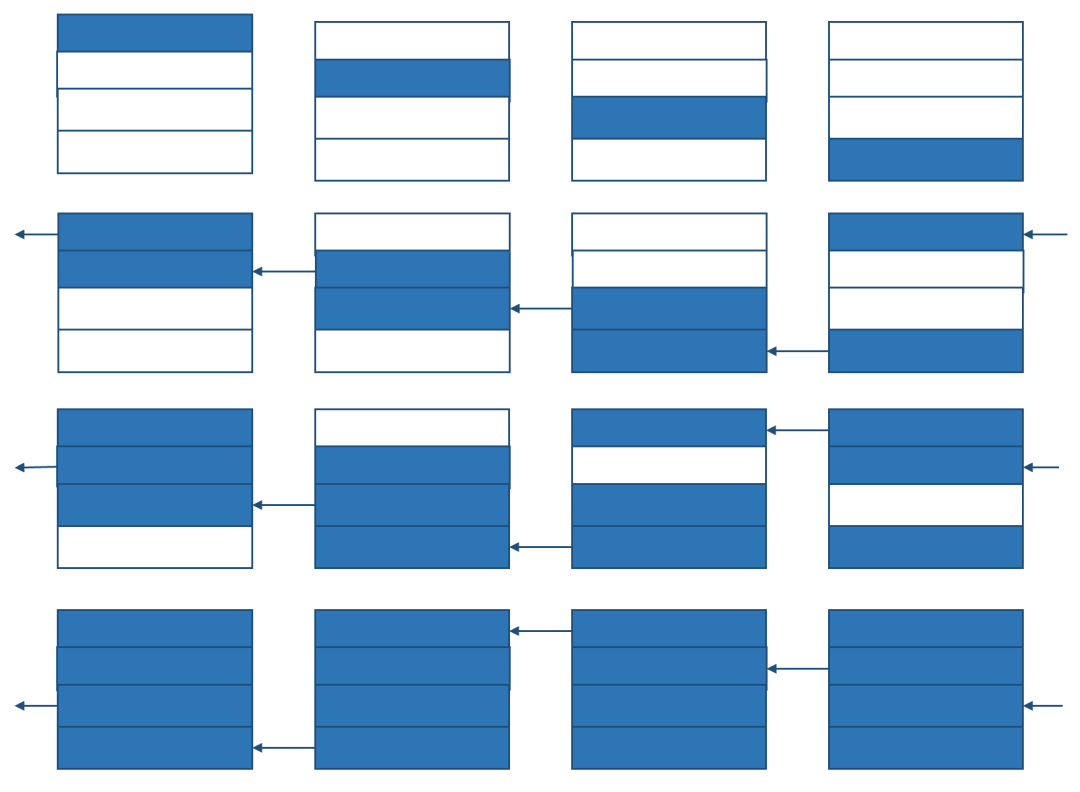
通信时间和ring reduce-scatter一样
所以ring all-reduce的时间为
理论上来说,要想完成reduce-scatter,每张卡需要向其他p-1张卡发送自己的大小为V/p的数据。(同时接收其他p-1张卡的V/p的数据)因此理论上最小的时间为
显存占用:每个设备上依然需要存大小为V的数据
代码实现
我去,真挺好。有些不应该分类在这里,但是先放在这里再说了
Pytorch - 分布式训练极简体验 - 颜挺帅的文章 - 知乎
Pytorch - 分布式通信原语(附源码) - 颜挺帅的文章 - 知乎
Pytorch - 手写allreduce分布式训练(附源码) - 颜挺帅的文章 - 知乎
Pytorch - 算子间并行极简实现(附源码) - 颜挺帅的文章 - 知乎
Pytorch - 多机多卡极简实现(附源码) - 颜挺帅的文章 - 知乎