入门
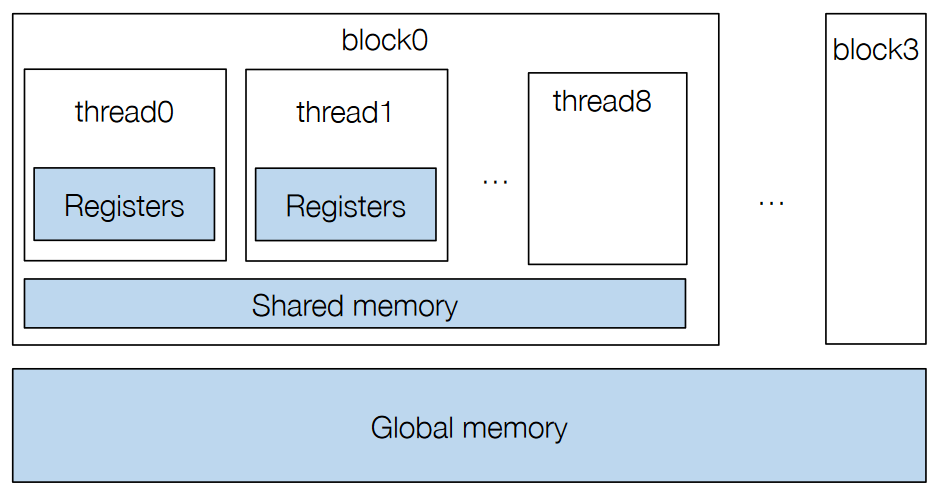
window sum with shared memory

将同一block里要访问的数据提前搬到shared memory里,减少从global memory读取的次数
矩阵乘
简单矩阵乘
相同的思路,利用内存层级,尽量从高层次的内存读取数据,降低对低层次内存的读取次数。

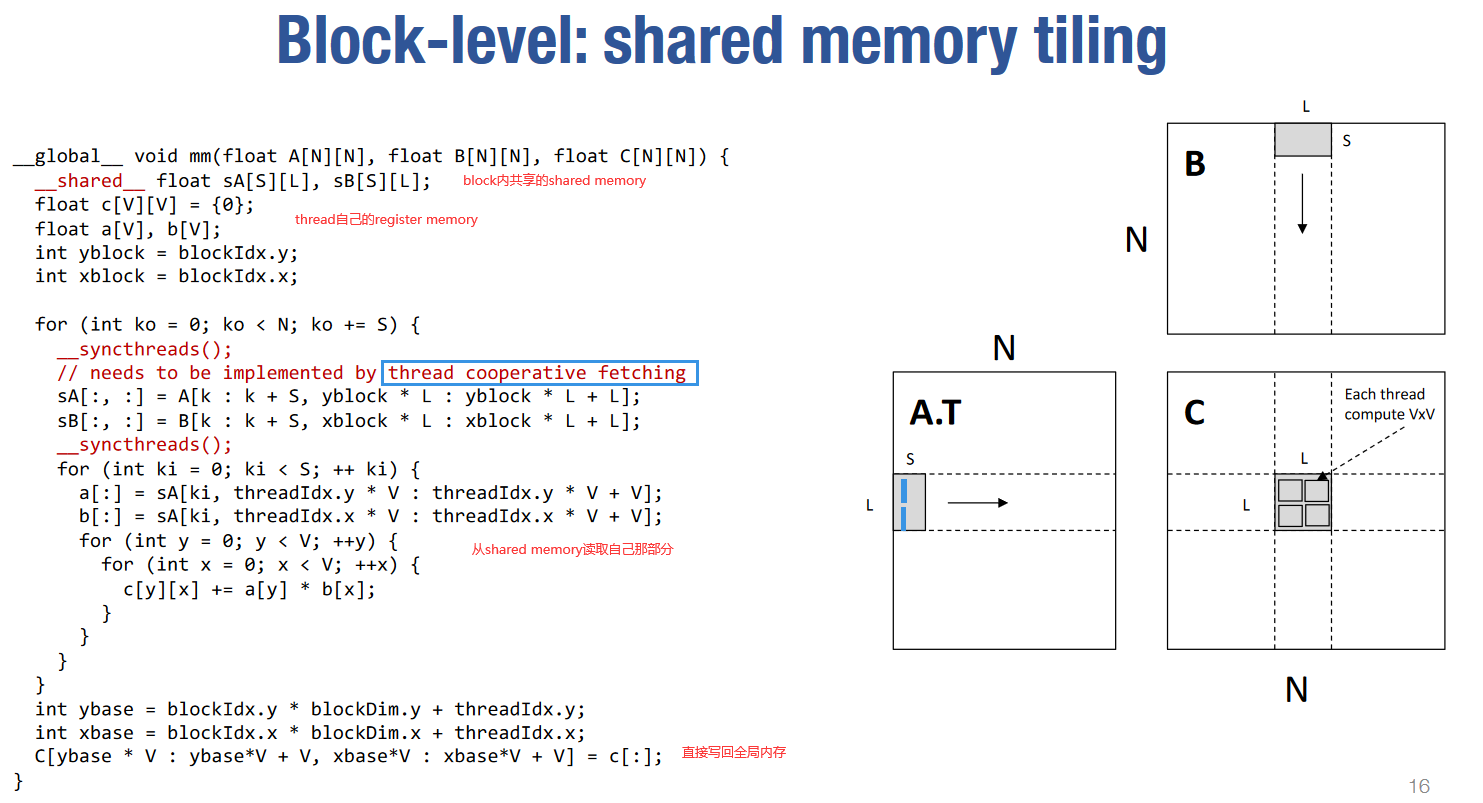
简单分析一下内存重用。如图中所示A,B,C都是NxN的方阵。
假如没有任何内存重用,计算C中每个元素需要读取2N个数据,因此总共需要读取
然后考虑对每个block,分别从A,B中读取LxS的小矩阵到shared memory,再将部分结果累加到C的LxL的分块上。一共需要从global memory读取
我们可不可以任意的增大L呢?应该不行…吧?不是太懂
然后考虑block内每个线程的内存重用。直接每次都从shared memory读取的话,需要
上面提到对shared memory的Thread Cooperative Fetching可以实现如下

这里只是在内存层级上简单的做了分块,让相邻元素的计算共享更多的内存。据ppt说还有别的优化方向
- Global memory continuous read
- Shared memory bank conflict
- Software pipelining
- Warp level optimizations
- Tensor Core
更多的矩阵乘优化
深入浅出GPU优化系列:GEMM优化(一) - 知乎
除了上面的矩阵分块,还有下面两个优化
- register和shared memory的bank conflict
- 解决方法,重排
- 数据的prefetch
- 在上面的矩阵乘代码中,计算之前都是搬运数据,它们前后依赖。搬运数据A+计算数据A+搬运数据B+计算数据B。虽然GPU中可以通过block的切换来掩盖这种latency,但是由于分配的shared memory比较多,活跃的block并不太多,这种延时很难被掩盖。因此需要预取
CUDA编程是如何工作的:NVIDIA官方经典_哔哩哔哩_bilibili
- 如何提升gpu利用率?
- 算力不是问题,内存带宽才是。计算速度>发送访存指令速度>内存带宽
- 内存的分页结构,访问不同页的数据的时钟周期代价更大。也可以把分页理解成类似于缓存的东西。例子中地址的高几位比特为行,低几位比特为列,这样访问相邻数据就会更快,但也可以不这样设计。
- 例子中给了一个图,以不同步长访问内存时获得的内存带宽为多少。看起来有两个缓存层次?或者说分页大小分别为64Byte和1024Byte?这个是让不同thread访问不同步长的地址数据测出来的嘛?
- 访存模式很重要,性能能差十倍
- grid block thread
- SIMT,同block的thread可以认为同时执行。根据thread id和block id索引自己的数据,有自己的状态。
- gpu把block里的相邻的thread组织成warp运行。一个SM会运行几个warp,几个相邻的warp一般会访问连续的内存,这样就提升了实际内存带宽。单个线程看起来随机的访存,在整体看来是连续访存的。
- 这里的案例:1warp有32个thread,一个SM同时执行四个warp,也就是128个thread,如果它们同时访问相邻的8Bytes,每次就刚好读取一页数据。能用满峰值内存带宽。所以一般来说block size最好不要低于128,即四个warp
- 然后给出了gpu资源示意图。重点是每个SM的可用资源,L1cache,share memory,计算单元,以及最多线程数。资源占用率也很重要,性能能差两倍
- 举例,gpu如何运行grid,如何在SM上分配block。每个SM上可以运行多个block,但是会尽量分开,因为每个SM资源有限。
- SM的资源限制
- 最大线程数,最大block数
- 总寄存器大小,register。各个thread私有
- 总share memory大小。share memory在block内共享
- 有限的加载数据带宽
- 举了一个计算两点平均距离的例子:先索引两个点,计算距离,然后累加到share memory里。其中SM的最大线程数,share memory,register是主要要关注的资源。线程是以block为单位放到SM上的,每个block都有自己的资源要求(thread number, share memory ,register)。而每个SM最多能放几个block,取决于上面三个资源(哪个最先耗尽)。
- 一个SM可以塞不同类型的block,比如某些移动数据的任务就不需要share memory。gpu可以自动帮你塞进去,但前提是你告诉它任务相互独立,或者避免任务相互依赖,提升并发性。可以将任务提交到不同的stream来表示任务之间的独立性,而不同的stream之间独立。
延时与带宽
对某个特定的计算,都是先把数据搬运上来,然后再计算。这样考虑的话,消耗时间应该是内存延迟+算数延迟。
- 算数指令延迟是一个算术操作从开始,到产生结果之间的时间。算术延迟一般 10~20 个时钟周期
- 内存指令延迟是当产生内存访问的时候,计算单元要等数据从内存拿到寄存器的时间。内存延迟 400~800 个时钟周期
但因为一般计算量足够大,所以我们有足够的并行度来隐藏延迟。这里解释一下隐藏延迟是什么意思。
我们想象一个水管,横截面是带宽B,单位是byte/s. 长度是时延T,单位是s.
如果我们想通过它传输M byte的数据,那么需要 M/B + T 的时间。如果M非常大,那么相对于M byte数据整体传输的时间,T就可以忽略不记。但是对于单个数据,延迟还是在那里的。
如果我们还是想通过这根水管传输数据,但是每秒只传输很少的数据,比如b byte/s,那么就没有充分利用水管的带宽传输资源。如果我们把带宽B理解为处理信息的速度(比如说每秒可以计算的浮点数),那么就是没有充分利用计算资源。利用率只有 b/B。
想象两根管子,第一根管子比较细长,长度表示内存延迟,截面表示内存带宽。第二根管子比较粗,长度表示算数延迟,截面宽表示FLOPs(每秒计算浮点数能力),或者说算数带宽(math bandwidth). 两根管子前后相接,从整体来看,数据流过的速度取决于最细的那根。